We'll pick it up from where the previous article ended to keep this one short. Here's the GitHub repository.
Our Trix editor component looks like this:
@props(['id', 'value', 'name', 'disabled' => false]) <input type="hidden" id="{{ $id }}_input" name="{{ $name }}" value="{{ $value?->toTrixHtml() }}"/><trix-editor id="{{ $id }}" input="{{ $id }}_input" {{ $disabled ? 'disabled' : '' }} {{ $attributes->merge(['class' => 'trix-content rounded-md shadow-sm border-gray-300 focus:border-indigo-300 focus:ring focus:ring-indigo-200 focus:ring-opacity-50']) }} x-data="{ upload(event) { const data = new FormData(); data.append('attachment', event.attachment.file); window.axios.post('/attachments', data, { onUploadProgress(progressEvent) { event.attachment.setUploadProgress( progressEvent.loaded / progressEvent.total * 100 ); }, }).then(({ data }) => { event.attachment.setAttributes({ url: data.image_url, }); }); } }" x-on:trix-attachment-add="upload"></trix-editor>This is listening to the trix-attachment-add event, which is fired by Trix when we attempt to upload a file, then we upload them to a POST /attachments endpoint using axios. From that endpoint's response, we get the image_url field and set that as an attribute in the Trix Attachment.
The route that handles the uploads looks like this:
Route::post('/attachments', function () { request()->validate([ 'attachment' => ['required', 'file'], ]); $path = request()->file('attachment')->store('trix-attachments', 'public'); return [ 'image_url' => Storage::disk('public')->url($path), ];})->middleware(['auth'])->name('attachments.store');We validate that the user is uploading a file and we then store it in a trix-attachments folder inside the public disk. Next, we get the URL to that file and return it back to the user as the image_url JSON field. Simple enough.
Now, let's add the Media Library package:
composer require spatie/laravel-medialibraryphp artisan vendor:publish --provider="Spatie\MediaLibrary\MediaLibraryServiceProvider" --tag="migrations"php artisan vendor:publish --provider="Spatie\MediaLibrary\MediaLibraryServiceProvider" --tag="config"These steps should add the package, publish its database migrations and config file. Make sure you have the required dependencies for Media Library's optimizations installed.
The Media Library package ships with its own model called Media. There are a couple of requirements when using this model, like its expectation to have a model associated to them, which would be a problem for us since we want to allow attachments to be created before the resource itself (think you're creating a post and adding attachments to it). To simplify things, let's add our own Attachment model. Whenever we upload an attachment, we'll associate the Media model to a corresponding Attachment model. That Attachment model will have its association as nullable so we can create them before the resource that will reference it.
We can add our model like this:
php artisan make:model Attachment -mfThe -m flag will create a corresponding migration for us, and the -f flag creates a model factory.
Let's change the created migration to add the fields we want:
Schema::create('attachments', function (Blueprint $table) { $table->id(); $table->nullableMorphs('record'); $table->string('caption')->nullable(); $table->timestamps();});Run the migrations:
php artisan migrateWe're making a record polymorphic relationship because we could potentially have other resources receiving attachments to its rich text fields as well.
Now, let's update the Attachment model to configure it to receive attachments:
namespace App\Models; use Illuminate\Database\Eloquent\Factories\HasFactory;use Illuminate\Database\Eloquent\Model;use Spatie\Image\Manipulations;use Spatie\MediaLibrary\HasMedia;use Spatie\MediaLibrary\InteractsWithMedia;use Spatie\MediaLibrary\MediaCollections\Models\Media; class Attachment extends Model implements HasMedia{ use HasFactory; use InteractsWithMedia; protected $casts = [ 'verified_at' => 'datetime', ]; protected $guarded = []; public function registerMediaConversions(Media $media = null): void { $this ->addMediaConversion('thumb') ->fit(Manipulations::FIT_CROP, 300, 300) ->nonQueued(); } public function record() { return $this->morphTo(); }}Now, let's create a new trait for the models that we want to associate attachments with. We'll call it HasAttachments:
namespace App\Models; trait HasAttachments{ public function syncAttachmentsMeta() { $this->content->attachments() ->filter(fn ($attachment) => $attachment->attachable instanceof Attachment) ->each(function ($attachment) { $attachment->attachable->update([ 'record' => $this, 'caption' => $attachment->node->getAttribute('caption'), ]); }); } public function attachments() { return $this->morphMany(Attachment::class, 'record'); }}We added the attachments relationship to the trait, but also a syncAttachmentsMeta method. That method is supposed to be called after we save the model with attachments (whenever we change the content rich text field). It will scan the document looking for attachments of the model Attachment and update the model meta data syncing with the caption in the rich text document. Although we're only interested in the caption attribute for now, you can see how you could extract other metadata from the document itself.
This reminds me we need to make the Attachment model an attachable as well. Attachables, in the Rich Text Laravel package, are models that have a rich text representation inside the documents. Let's add the contract and trait to it, we'll also override some of its methods, I'll explain in a bit:
namespace App\Models; // Other use statements...use Tonysm\RichTextLaravel\Attachables\Attachable;use Tonysm\RichTextLaravel\Attachables\AttachableContract; class Attachment extends Model implements HasMedia, AttachableContract{ // Other used traits... use Attachable; private $firstMediaCache; public function richTextPreviewable(): bool { return str_starts_with($this->getFirstMedia()->mime_type, 'image/'); } public function richTextFilename(): ?string { return $this->firstMedia()->file_name; } public function richTextFilesize() { return $this->firstMedia()->size; } public function richTextContentType(): string { return $this->firstMedia()->mime_type; } public function richTextRender(array $options = []): string { return view('trix._attachment', [ 'attachment' => $this, 'media' => $this->firstMedia(), 'options' => $options, ])->render(); } public function toTrixContent(): ?string { return null; } public function getPreviewableUrl(string $convertionName = null): string { return $this->firstMedia()->getFullUrl($convertionName); } public function firstMedia() { return $this->firstMediaCache ??= $this->getFirstMedia(); } public function setRecordAttribute($record) { $this->record()->associate($record); }}Alright, let's go over each method:
- richTextPreviewable: returns a boolean that indicates whether the attachment has a preview image associated. In our case, we're checking if the associated media has a content-type starting with
image/; - richTextFilename: returns the file name. Again, we're delegating that to the associated media;
- richTextFilesize: returns the file size in bytes. Which we're delegating that to the associated media;
- richTextContentType: returns the file content type. Also delegated to the associated media;
- richTextRender: returns the rendered HTML to show this attachment to users (not what renders inside Trix, but the actual final version);
- toTrixContent: returns the rendered HTML to rendered the attachment inside the Trix editor (what we show inside Trix);
The firstMedia, getPreviewableUrl, setRecordAttribute are actually custom methods, not needed for the Attachable contract. We're using the getPreviewableUrl method inside the view, which we'll explore shortly. The setRecordAttribute mutator will be used when we create the attachment, which we'll also explore shortly. And the firstMedia method is a helper method that caches the media instance on the current attachment the first time it's used so we avoid doing another database query when the attachable methods are used.
One thing you may have noticed is that we're returning null in the toTrixContent method. That's because Trix already knows how to render file attachments based on the file type for images and files (see here and here), so we don't actually need a custom HTML representation here. However, we're adding a custom view for the Attachment model for the final render because we cannot use the same template as remote images use (the ones that ship with the package) since some of the APIs changed.
The trix._attachment Blade template should look something like this:
<figure class="attachment attachment--{{ $attachment->richTextPreviewable() ? 'preview' : 'file' }} attachment--{{ $media->extension }}"> @if ($attachment->richTextPreviewable()) <img src="{{ $attachment->getPreviewableUrl() }}" /> @endif <figcaption class="attachment__caption"> @if ($attachment->caption) {{ $attachment->caption }} @else <span class="attachment__name">{{ $media->filename }}</span> <span class="attachment__size">{{ $media->humanReadableSize }}</span> @endif </figcaption></figure>That should be it. Now, let's change the upload endpoint to also create the Attachment model and associate the uploaded file as its media:
Route::post('attachments', function () { request()->validate([ 'attachment' => ['required', 'file'], ]); /** @var Attachment */ $attachment = Attachment::create([ 'record' => auth()->user(), ]); $media = $attachment->addMedia(request()->file('attachment')) ->toMediaCollection(); return [ 'attachable_sgid' => $attachment->richTextSgid(), 'image_url' => $media->getFullUrl(), ];})->name('attachments.store');Now, we're also returning a attachable_sgid field with the image_url. SGID is short for Signed Global IDs, which are essentually a string key that may represent any model (or object) in our application. You can think of it as a URL for your models. It's provided by the Globalid Laravel package, which the Rich Text Laravel package uses under the hood. That should be added to the Trix attachment in the front-end. Our final version there should be something like this:
@props(['id', 'value', 'name', 'disabled' => false]) <input type="hidden" id="{{ $id }}_input" name="{{ $name }}" value="{{ $value?->toTrixHtml() }}"/><trix-editor id="{{ $id }}" input="{{ $id }}_input" {{ $disabled ? 'disabled' : '' }} {{ $attributes->merge(['class' => 'trix-content rounded-md shadow-sm border-gray-300 focus:border-indigo-300 focus:ring focus:ring-indigo-200 focus:ring-opacity-50']) }} x-data="{ upload(event) { const data = new FormData(); data.append('attachment', event.attachment.file); window.axios.post('/attachments', data, { onUploadProgress(progressEvent) { event.attachment.setUploadProgress( progressEvent.loaded / progressEvent.total * 100 ); }, }).then(({ data }) => { event.attachment.setAttributes({ sgid: data.attachable_sgid, url: data.image_url, }); }); } }" x-on:trix-attachment-add="upload"></trix-editor>Now, let's add the HasAttachments trait to our Post model:
class Post extends Model{ // Other traits... use HasAttachments; // Other methods...}In our PostsController, let's make sure we call the syncAttachmentsMeta whenever a Post is created/updated, should be something like this:
class PostsController extends Controller{ // Other actions... public function store() { $post = auth()->user()->currentTeam->posts()->create( $this->postParams() + ['user_id' => auth()->id()] ); $post->syncAttachmentsMeta(); return redirect()->route('posts.show', $post); } public function update(Post $post) { $this->authorize('update', $post); tap($post) ->update($this->postParams()) ->syncAttachmentsMeta(); if (Request::wantsTurboStream() && ! Request::wasFromTurboNative()) { return Response::turboStream($post); } return redirect()->route('posts.show', $post); }}And with that, our app should be syncing our attachments from the rich text document to the Post model. What is nice about this that we can access our attachments from the Post model directly, without having to scan or even load the rich text document field, something like:
// returns a list of attachments without// having to go through the document...$post->attachmentsThat's it!
I hope you enjoyed this more "advanced" tutorial into the package. I actually have this running on my Turbo Demo App repository, you can see the Pull Request where I implemented this. It has a little bit more, the app there is using Stimulus instead of Alpine, but the idea is the same. And you can see the PR to the demo app from the previous article here.
For the next post in this Rich Text Laravel series I'm planning on adding server-side rendered syntax highlighting for the Trix code snippets in this application using Torchlight.
See you soon!
]]>class User extends Model{} class Team extends Model{} class Reviewer extends Model{ use SoftDeletes; public function reviewer() { return $this->morphTo(); } public function setReviewerAttribute($reviewer) { $this->reviewer()->associate($reviewer); }} class PullRequest extends Model{ public function reviewers() { return $this->hasMany(Reviewer::class); } public function syncReviewers(Collection $reviewers): void { DB::transaction(function () use ($reviewers) { $this->reviewers()->delete(); $this->reviewers()->saveMany($reviewers); }); }}Then, in the PullRequestReviewersController@update action, you would have something like:
class PullRequestReviewersController extends Controller{ public function store(PullRequest $pullRequest, Request $request) { $pullRequest->syncReviewers($this->reviewers($request)); } private function reviewers(Request $request) { // Returns new Reviewers based on the request... }}The PullRequestReviewersController::reviewers method will return a Collection of Reviewer instances. Building those new model instances can be tricky. Think about the form that is needed for this. The bare-minimum version of it would consist of a select field where you would list all Teams and Users as options. You could even group them in optgroup tags and label them accordingly:
<x-select name="reviewers[]" id="reviewers" multiple class="block mt-1 w-full"> <option value="" disabled selected>Select the reviewers...</option> <optgroup label="Teams"> @foreach ($teams as $team) <option value="{{ $team->id }}">{{ $team->name }}</option> @endforeach </optgroup> <optgroup label="Users"> @foreach ($users as $user) <option value="{{ $user->id }}">{{ $user->name }}</option> @endforeach </optgroup></x-select>Not so fast... teams and users may have colliding IDs. Both their Database tables have different sequences. Even if it didn't, let's say you're using UUIDs or something like that, how would you go about deciding which model the UUID belongs to when you're processing the request? All solutions I can think of would require some kind of ad-hoc differentiation between teams and users. Maybe you do something like <table>:<id>, so users options would render to user:1, user:2, etc., while teams options would render to something like team:1, team:2, etc.
Then, you'd have to encode that mapping logic to do the actual fetching. It's messy. There's a better way.
Globalids
The Globalid Laravel package solves this problem. This package is a port of a Rails gem called globalid. Instead of coming up with an ad-hoc solution that would probably be different every time we have a problem like this, we can solve it this way:
<x-select name="reviewers[]" id="reviewers" multiple class="block mt-1 w-full"> <option value="" disabled selected>Select the reviewers...</option> <optgroup label="Teams"> @foreach ($teams as $team) <option value="{{ $team->toGid()->toString() }}">{{ $team->name }}</option> @endforeach </optgroup> <optgroup label="Users"> @foreach ($users as $user) <option value="{{ $user->toGid()->toString() }}">{{ $user->name }}</option> @endforeach </optgroup></x-select>You would need to add the HasGlobalIdentification trait to both the Group and User models:
use Tonysm\Globalid\Models\HasGlobalIdentification; class User extends Model{ use HasGlobalIdentification;} class Team extends Model{ use HasGlobalIdentification;}The options' value fields would look something like this:
gid://laravel/App%5CModels%5CTeam/1gid://laravel/App%5CModels%5CUser/1The %5C here is the backslash (\) encoded to be URL-safe. This will work fine for a quick demo, but I'd highly recommend using something like Relation::enforceMorphMap() and avoiding using the model's FQCN for things like this. If you have a mapped morph, the package will use that. Something like this:
Relation::enforceMorphMap([ 'team' => Models\Team::class, 'user' => Models\User::class,]);And the options' values will then render like this:
gid://laravel/team/1gid://laravel/user/1Then, our backend can be simplified quite a lot, we can leverage the Globalids using the Locator Facade, like so:
use Tonysm\GlobalId\Facades\Locator; class PullRequestReviewersController extends Controller{ public function store(PullRequest $pullRequest, Request $request) { $pullRequest->syncReviewers($this->reviewers($request)); } private function reviewers(Request $request) { return Locator::locateMany(Arr::wrap($request->input('reviewers'))) ->map(fn ($reviewer) => Reviewer::make([ 'reviewer' => $reviewer, ]); }}That's nice, isn't it? The Locator::locateMany accepts a list of Globalids and will return its equivalent models. It's smart enough to only do a single query per model type to avoid unnecessary hops to the database and all. In this case, we used the Locator::locateMany but if we were only dealing with a single option, we could stick to the Locator::locate method, which would take a global ID and return the model instance based on that.
In our case, since we're only dealing with form payloads we could use the globalid path like that, but that's not really safe to use it as a route param, for instance. Instead of encoding the globalid to string, we could call the ->toParam() method, which would return a base64 URL-safe version of the globalid that you can use as a route param. Something like this:
Z2lkOi8vbGFyYXZlbC9ncm91cC8xThis could be useful if you were passing that as a route param like:
POST /pull-requests/123/reviewers/Z2lkOi8vbGFyYXZlbC9ncm91cC8xPreventing Tampering
Ok, all that is fine and all, but there's an issue with this implementation. It's not very secure. Users could tamper with the HTML form and start poking around with your payload. That's not cool. Would be cool if there was a way to prevent users from tampering with the globalids like that, right? Well, there is! It's called SignedGlobalids. The API is slightly the same, but instead of calling ->toGid() on the model, you would call ->toSgid(). Like following:
<x-select name="reviewers[]" id="reviewers" multiple class="block mt-1 w-full"> <option value="" disabled selected>Select the reviewers...</option> <optgroup label="Teams"> @foreach ($teams as $team) <option value="{{ $team->toSgid()->toString() }}">{{ $team->name }}</option> @endforeach </optgroup> <optgroup label="Users"> @foreach ($users as $user) <option value="{{ $user->toSgid()->toString() }}">{{ $user->name }}</option> @endforeach </optgroup></x-select>SignedGlobalids are cryptographically signed using a key derived from your app's APP_KEY, which means users cannot tamper with the form payload. Consuming this on your backend would then look like this:
use Tonysm\GlobalId\Facades\Locator; class PullRequestReviewersController extends Controller{ public function store(PullRequest $pullRequest, Request $request) { $pullRequest->syncReviewers($this->reviewers($request)); } private function reviewers(Request $request) { return Locator::locateManySigned(Arr::wrap($request->input('reviewers'))) ->map(fn ($reviewer) => Reviewer::make([ 'reviewer' => $reviewer, ]); }}The only difference is using locateManySigned instead of locateMany. Similarly, fetching a single resource would be locateSigned instead of the regular locate.
This can prevent users from tampering with the option values, but this does not prevent them from poking around in other places where you also use SignedGlobalids and find a signed option that they want to send in another form. If in your application you had another form that would also show them polymorphic options like that but to other models, for instance. They could then pick those options from the other form and use them on the one for reviewers. Since the options would be signed, your code would be tricked to accept it. That's not cool.
There are actually two ways you could go about it. When locating, you could tell the Locator that you're only interested in SignedGlobalids of the User model, for instance:
private function reviewers(Request $request){ return Locator::locateManySigned(Arr::wrap($request->input('reviewers')), [ 'only' => User::class, ]) ->map(fn ($reviewer) => Reviewer::make([ 'reviewer' => $reviewer, ]);}That would only locate SignedGlobalids for the User model, ignoring every other non-User SignedGlobalId you may have. You can also define purposes for SignedGlobaids. This way, you can prevent users from reusing options just by copying and pasting the values from one form to a totally different one. For instance, our reviewers form could render the options passing the for option to the toSgid():
<x-select name="reviewers[]" id="reviewers" multiple class="block mt-1 w-full"> <option value="" disabled selected>Select the reviewers...</option> <optgroup label="Teams"> @foreach ($teams as $team) <option value="{{ $team->toSgid(['for' => 'reviewers-form'])->toString() }}">{{ $team->name }}</option> @endforeach </optgroup> <optgroup label="Users"> @foreach ($users as $user) <option value="{{ $user->toSgid(['for' => 'reviewers-form'])->toString() }}">{{ $user->name }}</option> @endforeach </optgroup></x-select>Then, in our backend we would also have to specify the same purpose when locating the models, like this:
private function reviewers(Request $request){ return Locator::locateManySigned(Arr::wrap($request->input('reviewers')), [ 'for' => 'reviewers-form', ]) ->map(fn ($reviewer) => Reviewer::make([ 'reviewer' => $reviewer, ]);}If the purpose encoded and signed on the SignedGlobalid doesn't match with the purpose you specify when locating, it wouldn't work.
Alternatively, you could also specify how long this SignedGlobalid will be valid, for instance, which could be useful if you're generating a public access link for some resource but you don't want it to be available forever, which helps preventing data from leaking out of your app in some cases. Read more about SignedGlobalids here.
Globalids are very useful in all sorts of situations where you want to use polymorphism. I'm using that in the Rich Text Laravel package, for instance, to store references to models when you use them as attachments. Instead of serializing the model, we can store the URI to that model and use the Locator to find it for us when it's time to render the document again.
]]>If you prefer video, I've recording a tutorial based on this post:
So, let's dive right in.
The Demo App
Before we start talking about Trix and how the package integrates Laravel with it, let's create a basic journaling application, where users can keep track of their thoughts (or whatever they want, really).
To create the Laravel application, let's use Laravel's installer:
laravel new larajournalI'm gonna be using Laravel Sail, so let's publish the docker-compose.yml file:
php artisan sail:install --with=mysqlYou will need Docker and Docker Compose installed, so make sure you follow their instructions. Also, feel free to use php artisan serve or Laravel Valet, if you want to. It doesn't really matter for what we're trying to do here.
Let's start the services:
sail up -dWe should have both our database and the web server running. You can verify that by visiting http://localhost on your browser, or by listing the ps command, where all statuses should be Up:
sail psLet's install the Breeze scaffolding so we can have basic authentication and a protected area scaffold for us:
composer require laravel/breeze --devphp artisan breeze:installnpm install && npm run devNow, we'll create the model with migration and factory:
php artisan make:model Post -mfLet's add a title and acontentfield to thecreate_posts_table` migration we have just created:
Schema::create('posts', function (Blueprint $table) { $table->id(); $table->foreignId('user_id')->constrained(); $table->string('title'); $table->longText('content'); $table->timestamps();});We also added the Foreign Key to the users table so we can isolate each user's posts. Let's update the User model to add the posts relationship:
class User extends Authenticatable{ use HasApiTokens, HasFactory, Notifiable; // ... public function posts() { return $this->hasMany(Post::class); }}Now, lets edit the DatabaseSeeder to create a default user and some posts as well as some random posts so we can just check that we don't see other user's posts:
User::factory()->has(Post::factory(3))->create([ 'name' => 'Test User', 'email' => 'user@example.com',]); User::factory(5)->has(Post::factory(3))->create();Now, let's edit the PostFactory so we can instruct it how to create new fake posts:
<?php namespace Database\Factories; use App\Models\Post;use Illuminate\Database\Eloquent\Factories\Factory; class PostFactory extends Factory{ protected $model = Post::class; public function definition() { return [ 'title' => $this->faker->sentence(), 'content' => $this->faker->text(), ]; }}And edit the Post model to remove the mass-assignment protection:
class Post extends Model{ use HasFactory; protected $guarded = [];}Now, we can migrate and seed our database:
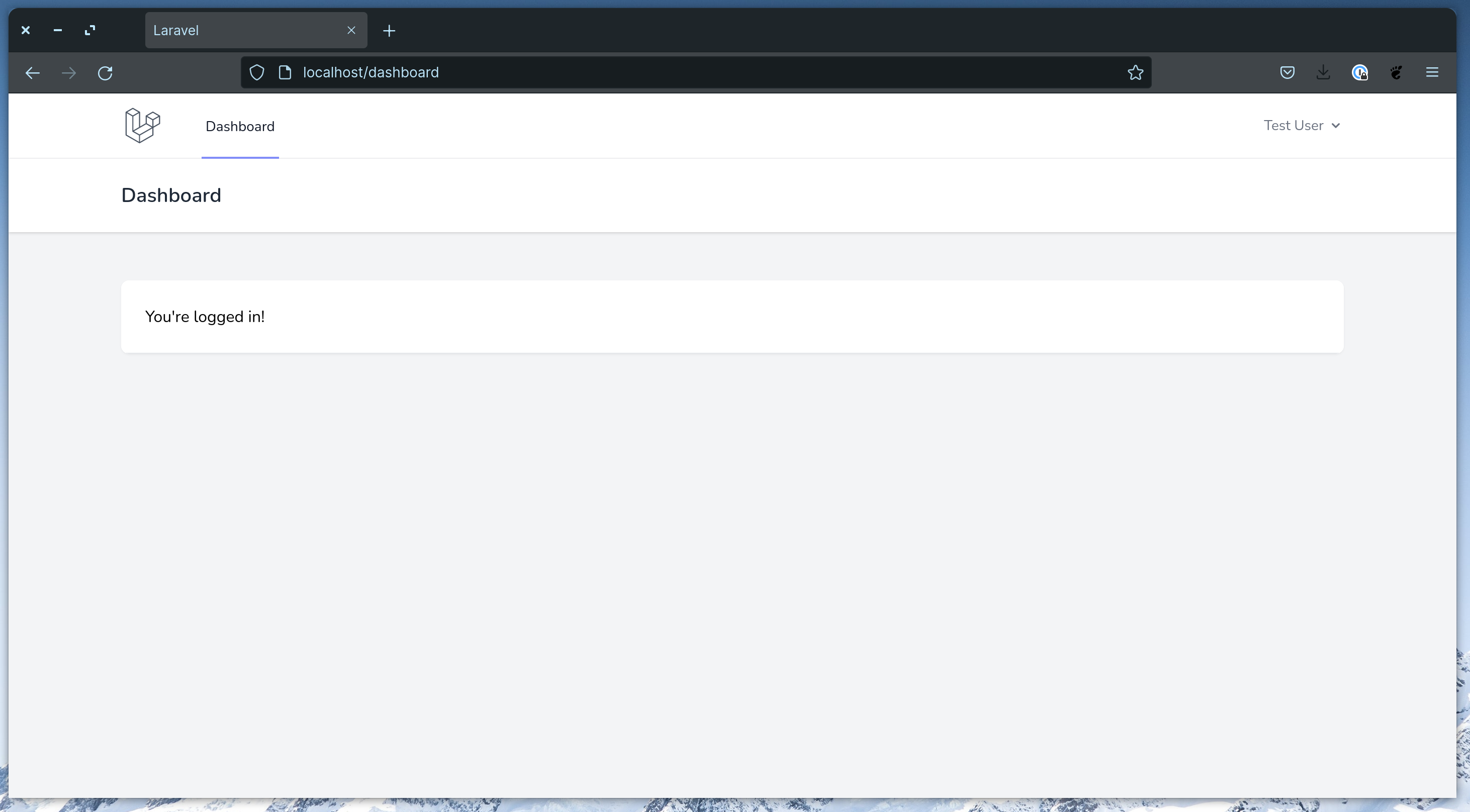
sail artisan migrate --seedNow, try to login with the user we created in our seeder. You should see the basic dashboard:
Now, let's pass down the user's post in the dashboard route at the web.php routes file:
Route::get('/dashboard', function () { return view('dashboard', [ 'posts' => auth()->user()->posts()->latest()->get(), ]);})->middleware(['auth'])->name('dashboard');Now, make use of the posts variable in the dashboard.blade.php Blade file:
<x-app-layout> <x-slot name="header"> <div class="flex items-center justify-between"> <h2 class="text-xl font-semibold leading-tight text-gray-800"> {{ __('Dashboard') }} </h2> <div> <a href="{{ route('posts.create') }}" class="px-4 py-2 font-semibold text-indigo-400 border border-indigo-300 rounded-lg shadow-sm hover:shadow">New Post</a> </div> </div> </x-slot> <div class="py-12"> <div class="mx-auto max-w-7xl sm:px-6 lg:px-8"> <div id="posts" class="space-y-5"> @forelse ($posts as $post) <x-posts.card :post="$post" /> @empty <x-posts.empty-list /> @endforelse </div> </div> </div></x-app-layout>This view makes use of two components, which we'll add now. First, add the resources/views/components/posts/card.blade.php:
<div class="bg-white border border-transparent rounded hover:border-gray-100 hover:shadow"> <a href="{{ route('posts.show', $post) }}" class="block w-full p-8"> <div class="pb-6 text-xl font-semibold border-b"> {{ $post->title }} </div> <div class="mt-4"> {{ Str::limit($post->content, 300) }} </div> </a></div>This card makes use of a posts.show named route and the dashboard.blade.php file makes use of a posts.create named route, which doesn't yet exist. Let's add that. First, create the PostsController:
php artisan make:controller PostsControllerThen, add this to the web.php routes file:
Route::resource('posts', Controllers\PostsController::class);We're adding a resource route because we'll make use of other resource actions as well.
There's still one component missing from our dashboard.blade.php view, the x-posts.empty. This component we'll have an empty message to show when there are no posts for the current user. Create the empty-list.blade.php file at resources/views/components/posts/:
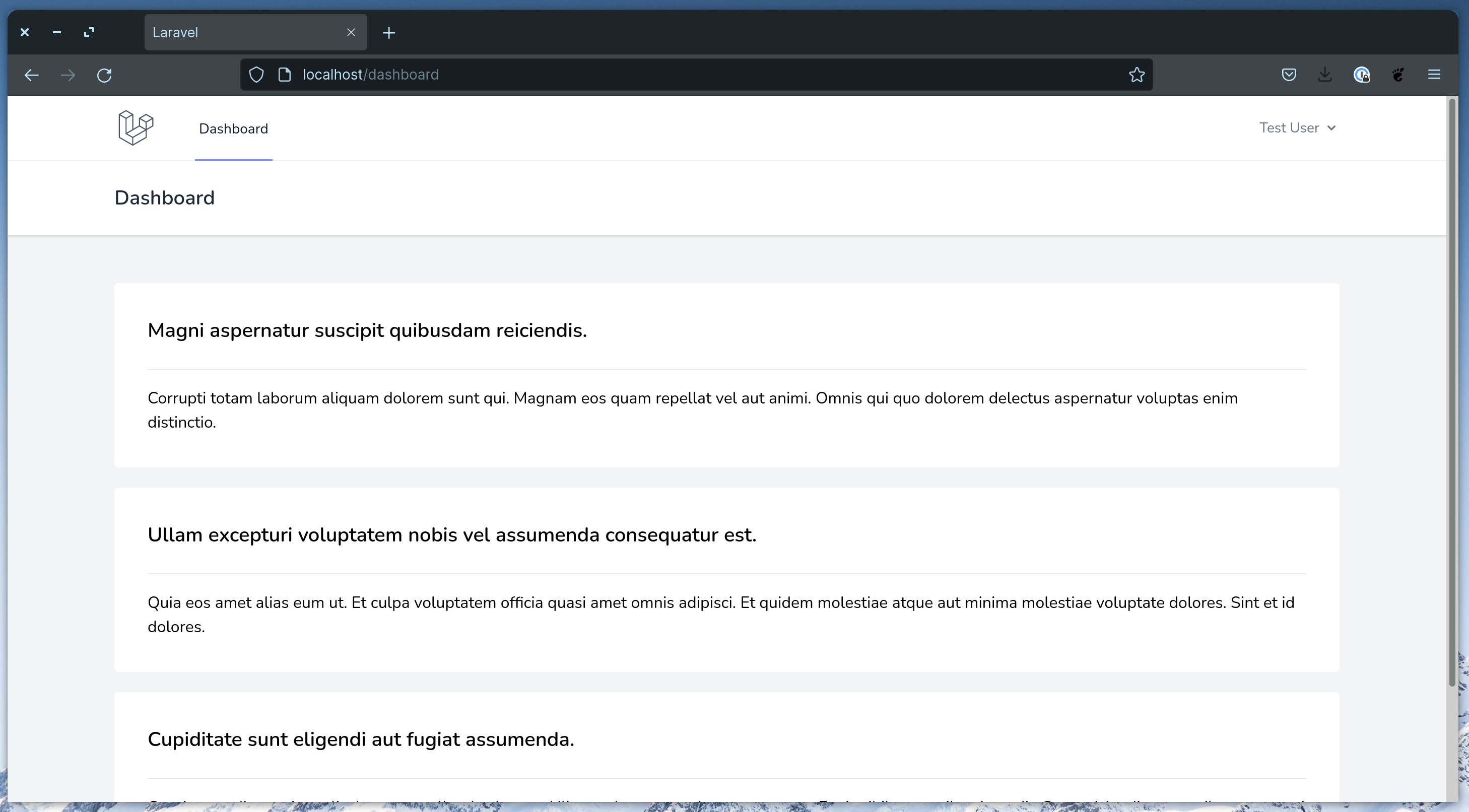
<div class="p-3 text-center"> <p>There are no posts yet.</p></div>Now, you should be able to see the latest 3 fake posts for the current user in the dashboard.
So far, so good. However, if we click in the "New Post" link, nothing happens yet. Let's add the create action to the PostsController:
/** * Show the form for creating a new resource. * * @return \Illuminate\Http\Response */public function create(){ return view('posts.create', [ 'post' => auth()->user()->posts()->make(), ]);}This makes use of a posts.create view which doesn't yet exist. Create a resources/views/posts/create.blade.php file with the following content:
<x-app-layout> <x-slot name="header"> <h2 class="text-xl font-semibold leading-tight text-gray-800"> <a href="{{ route('dashboard')}} ">Dashboard</a> / {{ __('New Post') }} </h2> </x-slot> <div class="py-12"> <div class="mx-auto max-w-7xl sm:px-6 lg:px-8"> <div class="p-8 bg-white rounded-lg"> <div id="create_post"> <x-posts.form :post="$post" /> </div> </div> </div> </div></x-app-layout>This makes use of a x-posts.form Blade component which we can create the resources/views/components/posts/form.blade.php file with the content:
<form method="POST" action="{{ route('posts.store') }}"> @csrf <!-- Post Title --> <div> <x-label for="title" :value="__('Title')" /> <x-input id="title" class="block w-full mt-1" placeholder="Type the title..." type="text" name="title" :value="old('title', $post->title)" required autofocus /> <x-input-validation for="title" /> </div> <!-- Post Content --> <div class="mt-4"> <x-label for="content" :value="__('Content')" class="mb-1" /> <x-forms.richtext id="content" name="content" :value="$post->content" /> <x-input-validation for="content" /> </div> <div class="flex items-center justify-between mt-4"> <div> <a href="{{ route('dashboard') }}">Cancel</a> </div> <div class="flex items-center justify-end"> <x-button class="ml-3"> {{ __('Save') }} </x-button> </div> </div></form>Almost all components used here comes with Breeze, except for the x-input-validation and the x-richtext components, which we'll add now. Create a resources/views/components/input-validatino.blade.php file with the contents:
@props('for') @if ($errors->has($for)) <p class="mt-1 text-sm text-red-800">{{ $errors->first($for) }}</p>@endifFor the richtext one, however, we're making it a simple textarea for now. Create the resources/components/forms/richtext.blade.php file with the content:
@props(['disabled' => false, 'value' => '']) <textarea {{ $disabled ? 'disabled' : '' }} {!! $attributes->merge(['class' => 'rounded-md shadow-sm border-gray-300 w-full focus:border-indigo-300 focus:ring focus:ring-indigo-200 focus:ring-opacity-50']) !!}>{{ $value }}</textarea>Ok, now if you click in the "New Posts" link, we should see the create posts form. To be able to create a post, let's add the store action to the PostsController:
/** * Store a newly created resource in storage. * * @param \Illuminate\Http\Request $request * @return \Illuminate\Http\Response */public function store(Request $request){ $request->user()->posts()->create($request->validate([ 'title' => ['required'], 'content' => ['required'], ])); return redirect()->route('dashboard');}Alright, if you try to create a post, you will get redirected back to the dashboard route and you should see the new post at the top. Nice!
Now, let's implement the posts.show route. So, add a show action the PostsController:
/** * Display the specified resource. * * @param \App\Models\Post $post * @return \Illuminate\Http\Response */public function show(Post $post){ return view('posts.show', [ 'post' => $post, ]);}And create the view file at resources/views/posts/show.blade.php with the content:
<x-app-layout> <x-slot name="header"> <h2 class="text-xl font-semibold leading-tight text-gray-800"> <a href="{{ route('dashboard') }}">Dashboard</a> / Post #{{ $post->id }} </h2> </x-slot> <div class="py-12"> <div class="mx-auto max-w-7xl sm:px-6 lg:px-8"> <div class="p-8 bg-white rounded-lg"> <div class="relative"> <div class="pb-6 text-xl font-semibold border-b"> {{ $post->title }} </div> <div class="absolute top-0 right-0" x-data x-on:click.away="$refs.details.removeAttribute('open')"> <details class="relative" x-ref="details"> <summary class="list-none" x-ref="summary"> <button type="button" x-on:click="$refs.summary.click()" class="text-gray-400 hover:text-gray-500"> <x-icon type="dots-circle" /> </button> </summary> <div class="absolute right-0 top-6"> <ul class="w-40 px-4 py-2 bg-white border divide-y rounded rounded-rt-0"> <li class="py-2"><a class="block w-full text-left" href="{{ route('posts.edit', $post) }}">Edit</a></li> <li class="py-2"><button class="block w-full text-left" form="delete_post">Delete</button></li> </ul> <form id="delete_post" x-on:submit="if (! confirm('Are you sure you want to delete this post?')) { return false; }" action="{{ route('posts.destroy', $post) }}" method="POST"> @csrf @method('DELETE') </form> </div> </details> </div> </div> <div class="mt-4"> {{ $post->content }} </div> </div> </div> </div></x-app-layout>This view uses an x-icon component, which uses a Heroicons SVG. You can create with this:
@props(['type']) <svg class="w-6 h-6" fill="none" stroke="currentColor" viewBox="0 0 24 24" xmlns="http://www.w3.org/2000/svg"> @if ($type === 'dots-circle') <path stroke-linecap="round" stroke-linejoin="round" stroke-width="2" d="M8 12h.01M12 12h.01M16 12h.01M21 12a9 9 0 11-18 0 9 9 0 0118 0z"></path> @endif</svg>With that, once you click in a post, you will see the entire post content. There's a dropdown here where you can see the "Edit" and "Delete" actions. Let's add the "destroy" action to the PostsController:
/** * Remove the specified resource from storage. * * @param \App\Models\Post $post * @return \Illuminate\Http\Response */public function destroy(Post $post){ $post->delete(); return redirect()->route('dashboard');}This should make the delete action work. Now, let's create the edit action so we can edit posts. Add the edit and update actions to the PostsController:
/** * Show the form for editing the specified resource. * * @param \App\Models\Post $post * @return \Illuminate\Http\Response */public function edit(Post $post){ return view('posts.edit', [ 'post' => $post, ]);} /** * Update the specified resource in storage. * * @param \Illuminate\Http\Request $request * @param \App\Models\Post $post * @return \Illuminate\Http\Response */public function update(Request $request, Post $post){ $post->update($request->validate([ 'title' => ['required', 'min:3', 'max:255'], 'content' => ['required'], ])); return redirect()->route('posts.show', $post);}Next, add the edit.blade.php view at resources/views/posts/edit.blade.php with the contents:
<x-app-layout> <x-slot name="header"> <h2 class="text-xl font-semibold leading-tight text-gray-800"> <a href="{{ route('dashboard')}} ">Dashboard</a> / {{ __('Edit Post #:id', ['id' => $post->id]) }} </h2> </x-slot> <div class="py-12"> <div class="mx-auto max-w-7xl sm:px-6 lg:px-8"> <div class="p-8 bg-white rounded-lg"> <div id="edit_post"> <x-posts.form :post="$post" /> </div> </div> </div> </div></x-app-layout>This will make use of the same form used to create posts, so we need to make some tweaks to it:
<form method="POST" action="{{ $post->exists ? route('posts.update', $post) : route('posts.store') }}"> @csrf @if ($post->exists) @method('PUT') @endif <!-- Post Title --> <div> <x-label for="title" :value="__('Title')" /> <x-input id="title" class="block w-full mt-1" placeholder="Type the title..." type="text" name="title" :value="old('title', $post->title)" required autofocus /> <x-input-validation for="title" /> </div> <!-- Post Content --> <div class="mt-4"> <x-label for="content" :value="__('Content')" class="mb-1" /> <x-forms.richtext id="content" name="content" :value="$post->content" /> <x-input-validation for="content" /> </div> <div class="flex items-center justify-between mt-4"> <div> @if ($post->exists) <a href="{{ route('posts.show', $post) }}">Cancel</a> @else <a href="{{ route('dashboard') }}">Cancel</a> @endif </div> <div class="flex items-center justify-end"> <x-button class="ml-3"> {{ __('Save') }} </x-button> </div> </div></form>With these changes, the form will post to the update action if the post model already exists or to the create action if it's a new instance. Similarly, the cancel link will lead the user to dashboard if it's a new instance or to the posts.show route if the post already exists.
That's it for the first part of this tutorial. We now have a fully functioning basic application where users can create keep track of their thoughts. We're still using just a simple textarea field. It's time to install Trix and the Rich Text Laravel package.
Use the Rich Text Laravel Package
To install the package, we can run:
composer require tonysm/rich-text-laravelNext, run the package's install command:
php artisan richtext:installThis will do:
- Publish the
create_rich_texts_tablemigration - Add
trixto thepackage.jsonfile as a dev dependency - Publish the Trix bootstrap file to
resources/js/libs/trix.js
Let's import that file in the resources/js/app.js file:
require('./bootstrap.js'); require('alpinejs'); require('./libs/trix.js');Then, add the Trix styles to the resources/css/app.css file:
/** These are specific for the tag that will be added to the rich text content */.trix-content .attachment-gallery > .attachment,.trix-content .attachment-gallery > rich-text-attachment { flex: 1 0 33%; padding: 0 0.5em; max-width: 33%;} .trix-content .attachment-gallery.attachment-gallery--2 > .attachment,.trix-content .attachment-gallery.attachment-gallery--2 > rich-text-attachment,.trix-content .attachment-gallery.attachment-gallery--4 > .attachment,.trix-content .attachment-gallery.attachment-gallery--4 > rich-text-attachment { flex-basis: 50%; max-width: 50%;} .trix-content rich-text-attachment .attachment { padding: 0 !important; max-width: 100% !important;} /** These are TailwindCSS specific tweaks */.trix-content { @apply w-full;} .trix-content h1 { font-size: 1.25rem !important; line-height: 1.25rem !important; @apply leading-5 font-semibold mb-4;} .trix-content a:not(.no-underline) { @apply underline;} .trix-content ul { list-style-type: disc; padding-left: 2.5rem;} .trix-content ol { list-style-type: decimal; padding-left: 2.5rem;} .trix-content img { margin: 0 auto;}Let's install Trix and compile the assets:
npm install && npm run devBy default, the Rich Text Laravel package ships with a suggested database structure. All Rich Text contents will live in the rich_texts table. Now, we need to migrate our content field from the posts table and create rich_text entries for each existing post. If you're starting a new application with the package, you can skip this part. I just wanted to demo how you could do a simple migration.
Create the migration:
php artisan make:migration migrate_posts_content_field_to_the_rich_text_tableChange the up method of the newly created migration to add the following content:
foreach (DB::table('posts')->oldest('id')->cursor() as $post){ DB::table('rich_texts')->insert([ 'field' => 'content', 'body' => '<div>' . $post->content . '</div>', 'record_type' => (new Post)->getMorphClass(), 'record_id' => $post->id, 'created_at' => $post->created_at, 'updated_at' => $post->updated_at, ]);} Schema::table('posts', function (Blueprint $table) { $table->dropColumn('content');});Since the RichText model is a polymorphic one, let's enforce the morphmap so we avoid storing the class's FQCN in the database by adding the following line in the boot method of theAppServiceProvider:
Relation::enforceMorphMap([ 'post' => \App\Models\Post::class,]);Now, let's add the HasRichText trait to the Post model and define our content field as a Rich Text field:
<?php namespace App\Models; use Illuminate\Database\Eloquent\Factories\HasFactory;use Illuminate\Database\Eloquent\Model;use Tonysm\RichTextLaravel\Models\Traits\HasRichText; class Post extends Model{ use HasFactory; use HasRichText; protected $guarded = []; protected $richTextFields = [ 'content', ];}Right now, the application is not working as you would expect. If you try to open it in the browser, you will see that it's not really behaving properly. First, we can see the <div> tag in the output both in the dashboard and in the posts.show routes. Let's fix the dashboard route first.
This will be a good opportunity to show a feature of the package: it can convert any Rich Text content to plain text! To achieve that, change the card component to be the following:
-{{ Str::limit($post->content, 300) }}+{{ Str::limit($post->content->toPlainText(), 300) }}Before, our content field was just a simple text field. Now, we get an instance of the RichText model, which forwards calls to the underlying Content class. The Content class has some really cool methods, such as the toPlainText() we see here.
With the card component taken care of, let's see what we can do for the posts.show route. It's still displaying the HTML tags. That's because Laravel's Blade will escape any HTML content when you're echoing out using double curly braces {{ }}, and that's not what we want. We need to let the HTML render on the page so any other tag such as h1s or ul created by Trix also display correctly.
Achieving that is relatively simple: use {!! !!} instead of {{ }}. However, there's a serious gotcha here that allows malicious users to exploit an XSS attack. We'll talk more about that in the next section. For now, let's make the naive change:
-{{ $post->content }}+{!! $post->content !!}And voilà! The HTML tags are no longer being escaped and the HTML content is rendering again. Cool.
One last piece before we jump to the next section. We are still using a textarea in our form. Let's replace it with the Trix editor. Trix is already installed and assets should have been compiled earlier, so I think we're ready. Change the contents of the richtext form component to this:
@props(['id', 'value', 'name', 'disabled' => false]) <input type="hidden" id="{{ $id }}_input" name="{{ $name }}" value="{{ $value?->toTrixHtml() }}" /><trix-editor id="{{ $id }}" input="{{ $id }}_input" {{ $disabled ? 'disabled' : '' }} {!! $attributes->merge(['class' => 'trix-content rounded-md shadow-sm border-gray-300 focus:border-indigo-300 focus:ring focus:ring-indigo-200 focus:ring-opacity-50']) !!}></trix-editor>Open up the browser again and you should see the Trix editor! Ain't this cool? Make some changes to the content and submit the form. Everything should be working as before.
There are two HTML elements here to make Trix work as we want: the input and the trix-editor elements. The input is hidden, so users don't actually see it, but this is the input that will be submitted by the browser containing the latest state of the HTML content for our field. We feed it using the toTrixHtml() method that we get from our Content class. Trix will take care of keeping the state from the editor in sync with the value of the input field, so you don't have to worry about that.
Now, let's handle the XSS attack vector we enabled by outputting non-escaped HTML content.
HTML Sanitization
Before we fix the issue, let's exploit it ourselves. Go to your browser, open the create posts form, open up your DevTools, find and delete the trix-editor element and change the hidden input type to text so the input is displayed. Now, replace its value with a script tag, like so:
<script>alert('hey, there');</script>Submit the form and got to that post's show page. Oh, noes. The JavaScript was executed by the browser. We don't want that, right? We can fix it with a technique called HTML Sanitization. We don't actually need to allow the entire HTML spec to be rendered. We only need a subset of it so our rich text content is displayed correctly. So, for one, we don't need to render any <script> tag. We cannot use something like PHP's strip_tags function, because that would get rid of all tags, so our <b> or <a> tags would be gone. We could maybe pass it a list of allowed HTML tags, but we could still be exploited using some HTML attributes.
Instead, let's use a package that will handle most of the work for us. That's mews/purifier:
composer require mews/purifierThe package gives us a clean() helper function that we can use to display sanitized. Let's change our posts/show.blade.php view to use that function:
-{!! $post->content !!}+{!! clean($post->content) !!}If you check that out in the browser you will notice that you no longer see the alert! So our problem was fixed. We still need to make some tweaks to the Sanitizer's default configs, but for now, that will do. Try out some rich text tweaks and see if they are displayed correctly. Most of them should.
Before we change the configs, let's explore one side of Trix that's not currently working: image uploads.
Simple Image Uploading
If you try to attach an image to Trix, it's not working out of the box. The image kinda shows up, but in a "pending" state, which means that this change was actually not made to the Trix document. See, Trix doesn't know how our application handles image upload, so it's up to us help it.
Let's use Alpine.js, which already comes installed with Breeze, to implement image uploading. First, let's cover the client-side of image uploading. Open up the richtext.blade.php component, and initialize Alpine in the trix-editor element:
<trix-editor x-data="{ // ... }"></trix-editor>Cool. Trix will dispatch a custom event called trix-attachment-add whenever you attempt to upload an attachment. We need to listen to that event and do the upload. The event will contain the file we have to upload as well as the Trix.Attachment instance object which we'll use later to set some attributes on it so we can tell Trix the attachment is no longer pending so it can update the Document state:
@props(['id', 'value', 'name', 'disabled' => false]) <input type="hidden" id="{{ $id }}_input" name="{{ $name }}" value="{{ $value?->toTrixHtml() }}"/><trix-editor id="{{ $id }}" input="{{ $id }}_input" {{ $disabled ? 'disabled' : '' }} {!! $attributes->merge(['class' => 'trix-content rounded-md shadow-sm border-gray-300 focus:border-indigo-300 focus:ring focus:ring-indigo-200 focus:ring-opacity-50']) !!} x-data="{ upload(event) { const data = new FormData(); data.append('attachment', event.attachment.file); window.axios.post('/attachments', data, { onUploadProgress(progressEvent) { event.attachment.setUploadProgress( progressEvent.loaded / progressEvent.total * 100 ); }, }).then(({ data }) => { event.attachment.setAttributes({ url: data.image_url, }); }); } }" x-on:trix-attachment-add="upload"></trix-editor>That's cool. We're sending a request to POST /attachments with an attachment field and we expect a image_url in the response data. Let's implement the server-side for that. We'll simply add a route Closure to our web.php routes file for now:
Route::post('/attachments', function () { request()->validate([ 'attachment' => ['required', 'file'], ]); $path = request()->file('attachment')->store('trix-attachments', 'public'); return [ 'image_url' => Storage::disk('public')->url($path), ];})->middleware(['auth'])->name('attachments.store');If you try to attach an image now, uploading should just work! But there should be a problem when you visit that post's show page: the image is broken. Let's publish the config so we can tweak it a little bit:
php artisan vendor:publish --provider="Mews\Purifier\PurifierServiceProvider"Now, open up the /config/purifier.php and replace its contents:
<?php return [ 'encoding' => 'UTF-8', 'finalize' => true, 'ignoreNonStrings' => false, 'cachePath' => storage_path('app/purifier'), 'cacheFileMode' => 0755, 'settings' => [ 'default' => [ 'HTML.Doctype' => 'HTML 4.01 Transitional', 'HTML.Allowed' => 'rich-text-attachment[sgid|content-type|url|href|filename|filesize|height|width|previewable|presentation|caption|data-trix-attachment|data-trix-attributes],div,b,strong,i,em,u,a[href|title|data-turbo-frame],ul,ol,li,p[style],br,span[style],img[width|height|alt|src],del,h1,blockquote,figure[data-trix-attributes|data-trix-attachment],figcaption,pre,*[class]', 'CSS.AllowedProperties' => 'font,font-size,font-weight,font-style,font-family,text-decoration,padding-left,color,background-color,text-align', 'AutoFormat.AutoParagraph' => true, 'AutoFormat.RemoveEmpty' => true, ], 'test' => [ 'Attr.EnableID' => 'true', ], "youtube" => [ "HTML.SafeIframe" => 'true', "URI.SafeIframeRegexp" => "%^(http://|https://|//)(www.youtube.com/embed/|player.vimeo.com/video/)%", ], 'custom_definition' => [ 'id' => 'html5-definitions', 'rev' => 1, 'debug' => false, 'elements' => [ // http://developers.whatwg.org/sections.html ['section', 'Block', 'Flow', 'Common'], ['nav', 'Block', 'Flow', 'Common'], ['article', 'Block', 'Flow', 'Common'], ['aside', 'Block', 'Flow', 'Common'], ['header', 'Block', 'Flow', 'Common'], ['footer', 'Block', 'Flow', 'Common'], // Content model actually excludes several tags, not modelled here ['address', 'Block', 'Flow', 'Common'], ['hgroup', 'Block', 'Required: h1 | h2 | h3 | h4 | h5 | h6', 'Common'], // http://developers.whatwg.org/grouping-content.html ['figure', 'Block', 'Optional: (figcaption, Flow) | (Flow, figcaption) | Flow', 'Common'], ['figcaption', 'Inline', 'Flow', 'Common'], // http://developers.whatwg.org/the-video-element.html#the-video-element ['video', 'Block', 'Optional: (source, Flow) | (Flow, source) | Flow', 'Common', [ 'src' => 'URI', 'type' => 'Text', 'width' => 'Length', 'height' => 'Length', 'poster' => 'URI', 'preload' => 'Enum#auto,metadata,none', 'controls' => 'Bool', ]], ['source', 'Block', 'Flow', 'Common', [ 'src' => 'URI', 'type' => 'Text', ]], // http://developers.whatwg.org/text-level-semantics.html ['s', 'Inline', 'Inline', 'Common'], ['var', 'Inline', 'Inline', 'Common'], ['sub', 'Inline', 'Inline', 'Common'], ['sup', 'Inline', 'Inline', 'Common'], ['mark', 'Inline', 'Inline', 'Common'], ['wbr', 'Inline', 'Empty', 'Core'], // http://developers.whatwg.org/edits.html ['ins', 'Block', 'Flow', 'Common', ['cite' => 'URI', 'datetime' => 'CDATA']], ['del', 'Block', 'Flow', 'Common', ['cite' => 'URI', 'datetime' => 'CDATA']], // RichTextLaravel ['rich-text-attachment', 'Block', 'Flow', 'Common'], ], 'attributes' => [ ['iframe', 'allowfullscreen', 'Bool'], ['table', 'height', 'Text'], ['td', 'border', 'Text'], ['th', 'border', 'Text'], ['tr', 'width', 'Text'], ['tr', 'height', 'Text'], ['tr', 'border', 'Text'], ], ], 'custom_attributes' => [ ['a', 'target', 'Enum#_blank,_self,_target,_top'], // RichTextLaravel ['a', 'data-turbo-frame', 'Text'], ['img', 'class', new HTMLPurifier_AttrDef_Text()], ['rich-text-attachment', 'sgid', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'content-type', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'url', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'href', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'filename', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'filesize', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'height', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'width', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'previewable', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'presentation', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'caption', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'data-trix-attachment', new HTMLPurifier_AttrDef_Text], ['rich-text-attachment', 'data-trix-attributes', new HTMLPurifier_AttrDef_Text], ['figure', 'data-trix-attachment', new HTMLPurifier_AttrDef_Text], ['figure', 'data-trix-attributes', new HTMLPurifier_AttrDef_Text], ], 'custom_elements' => [ ['u', 'Inline', 'Inline', 'Common'], // RichTextLaravel ['rich-text-attachment', 'Block', 'Flow', 'Common'], ], ], ];If you refresh the browser now you will see that our img tag is now wrapped with a figure tag. But it's still not working, right?
That's because we need to symlink the storage folder to our public/ directory locally so images uploaded to the public disk using the local driver are displayed correctly:
# If you're using Sail:sail artisan storage:link # Otherwise, use this:php artisan storage:linkThat should fix it! Great.
This will do it for an introductory guide, I think. I plan to write more advanced guides like User mentions and advanced image uploading using Spatie's Media Library package. I'll see you on the next post.
]]>Some cool design patterns I've learned recently:
— Tony Messias (@tonysmdev) May 8, 2021
- Method Object
- Double Dispatch (aka. Duet or Pas de Deux)
- Pluggable Behavior
🤓
And Freek Van der Herten mentioned that I could cover them as blogposts. Here's is the first one. Well, technically, the second one. See, the first pattern I mentioned there called "Method Object" was already covered here in this blog in the post titled "When Objects Are Not Enough". Same idea. Which is cool. I've updated the post to add this reference.
Now to Double Dispatch!
Introduction
The computation of a method call is only dependent on the object receiving the method call. Most of the time that's enough. However, sometimes we need the computation to also depend on the argument being passed to the method call.
Think you have two hierarchies of objects interacting with each other and the computation of these interactions depends on both objects, not only in one of them. Maybe some examples will make this clearer.
We're going to TDD our way through this pattern using Pest. Feel free to use whatever you want. All classes are in the same file as the test for the sake of the demo.
Example: Adding Integers and Floats
Let's get to the first example: adding numbers. For this example, let's imagine we are building the base classes for numbers in a language and that our language is not able to add primitives of the different types.
We'll start with the use case of adding only integers:
declare(strict_types = 1); test('adds integers', function () { $first = new IntegerNumber(40); $second = new IntegerNumber(2); $this->assertSame(42, $first->add($second)->value);});Let's add IntegerNumber class to the top of the test file to make the test pass (right below the declare() call):
class IntegerNumber{ public function __construct(public int $value) {} public function add($number) { return new IntegerNumber($this->value + $number->value); }}That works. Notice that we added a declare(strict_types = 1); to the PHP file. I did this because PHP is very smart and is able to sum integers and floats, so I wanted to force us to manually cast the values for the purpose of this example.
Let's add test for adding floats:
test('adds floats', function () { $first = new FloatNumber(40.0); $second = new FloatNumber(2.0); $this->assertSame(42.0, $first->add($second)->value);});And, to make it pass, let's add the FloatNumber class:
class FloatNumber{ public function __construct(public float $value) {} public function add($number) { return new FloatNumber($this->value + $number->value); }}Our tests should be green. So far, so good. Let's add our first cross-addition: adding integers and floats.
test('adds integers and floats', function () { $first = new IntegerNumber(40); $second = new FloatNumber(2.0); $this->assertSame(42, $first->add($second)->value); $this->assertSame(42.0, $second->add($first)->value);});OK, how can we get that one working? The answer is: Double Dispatch. The pattern states the following:
Send a message to the argument. Append the class name of the receiver to the selector. Pass the receiver as an argument. (Kent Beck in "Smalltalk Best Practice Patterns", pg. 56)
This was in Smalltalk. For us, the selector is the method name (or close enough). Let's apply the pattern. First, let's handle our first use case adding integers:
class IntegerNumber{ public function __construct(public int $value) {} public function add($number) { return $number->addInteger($this); } public function addInteger(IntegerNumber $number) { return new IntegerNumber($this->value + $number->value); }}If we run the first test, it should still pass. That's because we're adding two instances of the IntegerNumber class. The receiver of the add() message will call the addInteger on the argument and pass itself to it. At that point, we have two integer primitives, so we can return a new instance summing the primitives.
Now, let's make a similar change to the FloatNumber class:
class FloatNumber{ public function __construct(public float $value) {} public function add($number) { return $number->addFloat($this); } public function addFloat(FloatNumber $number) { return new FloatNumber($this->value + $number->value); }}Our first two tests should be passing now. Nice! Let's now add the cross methods. First, an integer only knows how to add other integers (primitives). Similarly, floats should only know how to add their own primitives. However, integers should be able to convert themselves to floats and vice-versa. This will allow us to add floats and integers together.
When a Float Number instance receives the add() message with an instance of the IntegerNumber class, it will call the addFloat on the argument, and pass itself to it. So we need an addFloat(FloatNumber $number) method on the IntegerNumber class. As we discussed, an IntegerNumber number doesn't know how to sum floats, but it knows how to convert itself to a float. And who knows how to add two floats together? The FloatNumber instance! So, at that point, the IntegerNumber instance will cast itself to Float and call the addFloat() on the float number instance with that. Then, the float number does the primitive addition and returns a new instance of a FloatNumber.
Similarly, when an Integer Number instance receives the add() message with an instance of a FloatNumber class, it will call addInteger on it, passing itself to it. Then, the Float Number will cast itself to an integer and pass that back to the integer calling addInteger. Again, at that point, Integer can do the primitive addition and return a new instance of an IntegerNumber class.
Here's the final solution for both the IntegerNumber and the FloatNumber classes:
class IntegerNumber{ public function __construct(public int $value) {} public function add($number) { return $number->addInteger($this); } public function addInteger(IntegerNumber $number) { return new IntegerNumber($this->value + $number->value); } public function addFloat(FloatNumber $number) { return $number->addFloat($this->asFloat()); } private function asFloat() { return new FloatNumber(floatval($this->value)); }} class FloatNumber{ public function __construct(public float $value) {} public function add($number) { return $number->addFloat($this); } public function addFloat(FloatNumber $number) { return new FloatNumber($this->value + $number->value); } public function addInteger(IntegerNumber $number) { return $number->addInteger($this->asInteger()); } public function asInteger() { return new IntegerNumber(intval($this->value)); }}
It works! Nice. If you're like me, you're now delighted with such a sophisticated implementation.
Isn't this cool?
Example: Star Trek
OK, the numbers example was cool and all, but chances are we're not implementing a language. Is this even useful anywhere else? Well, the important thing about a pattern is the design, not the implementation. You can re-use the same design on different contexts.
Let's say we're building a Star Trek game. We'll control a spaceship and there might be some enemies along the way, so they have to fight. Some enemies will be critical while others will not cause any damage depending on the spaceship.
So we have two hierarchies at play here: Spaceships and Enemies. And the computation of the combat depends on both of them. Perfect use case for the Double Dispatch pattern.
Let's start with a simple case: an asteroid and a space shuttle. The asteroid damages the shuttle, but not critically:
test('asteroid damages shuttle', function () { $spaceship = new Shuttle(hitpoints: 100); $enemy = new Asteroid(); $spaceship->fight($enemy); $this->assertEquals(90, $spaceship->hitpoints);});The implementation would be something like this:
class Shuttle{ public function __construct(public int $hitpoints) {} public function fight($enemy) { $this->hitpoints -= $enemy->damage(); }} class Asteroid{ public function damage() { return 10; }}The test should be green. Nice. Let's add another spaceship. The USS Voyager should not receive any damage from an Asteroid.
test('asteroid does not damage uss voyager', function () { $spaceship = new UssVoyager(hitpoints: $initialHitpoints = 100); $enemy = new Asteroid(); $spaceship->fight($enemy); $this->assertSame($initialHitpoints, $spaceship->hitpoints);});Let's implement our new spaceship:
class UssVoyager{ public function __construct(public int $hitpoints) {} public function fight($enemy) { // Nothing happens. }}Our tests should be green now. Uhm... it looks weird, right? Let's add another enemy and see if it this design still works. Our new enemy is a Borg Cube. Borgs will assimilate any spaceship (resistance is futile).
Let's start with a test for the Shuttle facing the Borg Cube:
test('borg cube critically damages the shuttle', function () { $spaceship = new Shuttle(hitpoints: 100); $enemy = new BorgCube(); $spaceship->fight($enemy); $this->assertSame(0, $spaceship->hitpoints);});Let's implement the Borg Cube enemy:
class BorgCube{ public function damage() { return 100; }}OK, our test should be green. Let's add another test before we refactor this. Borgs will also assimilate the USS Voyager:
test('borg cube critically damages the uss voyager', function () { $spaceship = new UssVoyager(hitpoints: 100); $enemy = new BorgCube(); $spaceship->fight($enemy); $this->assertSame(0, $spaceship->hitpoints);});And... red. Tests are failing. That's because so far nothing damaged the USS Voyager. I think it's time to apply the pattern. First, let's send a message to the enemy, append the spaceship name to the message and pass it along as an argument:
class Shuttle{ public function __construct(public int $hitpoints) {} public function fight($enemy) { $enemy->fightShuttle($this); }} class UssVoyager{ public function __construct(public int $hitpoints) {} public function fight($enemy) { $enemy->fightUssVoyager($this); }} class Asteroid{ public function fightShuttle(Shuttle $shuttle) { $shuttle->hitpoints -= 10; } public function fightUssVoyager(UssVoyager $ussVoyager) { // Does nothing... }} class BorgCube{ public function fightShuttle(Shuttle $shuttle) { $shuttle->hitpoints = 0; } public function fightUssVoyager(UssVoyager $ussVoyager) { $ussVoyager->hitpoints = 0; }}If we extract an Enemy interface here, we would have something like this:
interface Enemy{ public function fightShuttle(Shuttle $shuttle); public function fightUssVoyager(UssVoyager $ussVoyager);}If we add a new enemy to the system, we know we only have to implement the enemy interface and it should Just Work™. Adding a new spaceship? We also need to add it to the enemy interface.
Conclusion
This is not always flowers and sunshine, though. There is a bunch of indirection at play here. The alternative would involve a couple if/switch statements around, so I think it's worth it.
You might think this is similar to the Visitor Pattern, and that's true. The Visitor Pattern solves the problem when Double Dispatch cannot be used (see the Wikipedia for Double Dispatch.) Also make sure to check out this video on the subject.
I had fun writing this piece. And I'm having a lot of fun reading the book. Let me know what you think.
]]>This Actions pattern states that logic should be wrapped in Action classes. The idea isn't new as other communities have been advocating for "Clean Architecture" where each "Use Case" (or Interactor) would be its own class. It's similar. But is it really what OOP is about?
If you're interested in a TL;DR version of this article, here it is:
- Smalltalk was one of the first Object-Oriented Programming Languages out there. It's where ideas like inheritance and message-passing came from (or at least where they got popular, from what I understand);
- According to Alan Kay, who coined the term "Object-Oriented Programming", objects are not enough. They don't give us an Architecture. Objects are all about the interactions between them and, for large scale systems, you need to be able to break down your applications in modules in a way that allows you to turn off a module, replace it, and turn it back on without bringing the entire application down. That's where he mentions the idea of encapsulating "messages" in classes where each instance would be a message in our systems, backing up the idea of having "Action" classes or "Interactors" in the Clean Architecture approach;
Continue reading if this sparks your interest.
What Are Objects?
An object has state and operations combined. At the time where it was coined, applications were built with data structures and procedures. By combining state and operations in a single "entity" called an "object" you give this entity an anthropomorphic meaning. You can think of objects as "little beings". They know some information (state) and they can respond to messages sent to them.
Such messages usually take the form of method calls and this is the idea that got propagated in other languages such as Java or C++. Joe Armstrong, one of the co-designers of Erlang, wrote in the Elixir forum that, in Smalltalk, messages "were not real messages but disguised synchronous function calls", and this mistake was also repeated in other languages, according to him.
One common misconception seems to be on thinking of objects as types. Types (or Abstract Data Types, which are "synonyms" - or close enough - for the purpose of this writing) aren't objects. As Kay points out in this seminar, the way objects are used these days is a bit confusing because it's intertwined with another idea from the '60s: data abstraction (ADTs). They are similar in some ways, particularly in implementation, but its intent is different.
The intent of ADT, according to Kay, was to take a system in Pascal/FORTRAN that's starting to become difficult to change (where the knowledge has been spread out in procedures) and wrap envelopes around data structures, invoking operations by means of procedures in order to get it to be a bit more representation independent.
This envelope of procedures is then wrapped around the data structure in an effort to protect it. But then this new structure that was created is now treated as a new data structure in the system. The result is that the programs don't get small. One of the results of OOP is that programs tend to get smaller.
To Kay, Java and C++ are not good examples of "real OOP". Barbara Liskov points out that Java was a combination of ADT with the inheritance ideas from Smalltalk. To be honest, I can't articulate this difference between ADTs and Objects in OOP quite well. Maybe because I first learned OOP in Java.
One more fun fact about the early days: they were not sure if they were going to be able to implement polymorphism in strongly-typed languages (where the idea of ADT came from), since the compiler would link the types explicitly and nobody wanted to rewrite sorting functions for each different type, for example (Liskov mentions this in the already mentioned talk). As I see it, that's the problem interfaces/protocols and generics solve. In a way, I think of these things as ways to achieve late-binding in strongly-typed languages (and I also think this is true for some design patterns).
Kay doesn't seem to appreciate what this mix of ADT and OOP did to the original idea. He seems to agree with Armstrong. To Kay, Object-Oriented is about three things:
- Messaging (or message-passing);
- Local retention and protection and hiding of state-process (or encapsulation); and
- Extreme late-binding.
These are the traits of OOP, or "Real OOP" - as Kay calls it. The term got "hijacked" and somehow turned into, as Armstrong puts it, "organizing code into classes and methods". That's not what "Real OOP" is about.
Objects tend to be larger things than mere data structures. They tend to be entire components. Active machines that fit together with other active machines to make a new kind of structure.
Kay has an exercise of adding a negation to "core beliefs" in our field to try and identify what these things are really about. Take "big data", for instance. If we add a "not" to it, it says "NOT big data", so if it's NOT about big data, what would it be about? Well, "big meaning", as Kay points out.
If we do that with "Object-Oriented Programming" and add a "not" to it, we get "NOT Object-Oriented Programming", and if it's not about object-orientation, what is it about? Well, it seems to be Messages. That seems to be the core idea of OOP. Even though they were promoting inheritance a lot in the Smalltalk days. And yes, messaging was a big part of it too, but since it was practically "disguised synchronous function calls", they didn't get the main stage when the idea got mainstream.
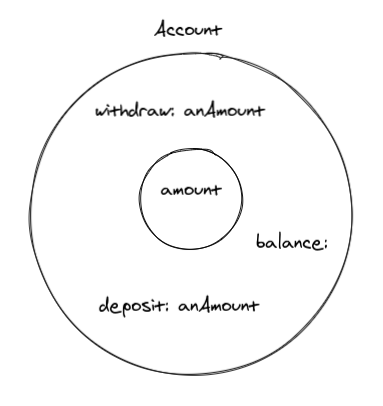
Let's use a banking software as an example. We're going to model an Account. An account needs to keep track of its balance. And it has to be able to handle withdraw, as long as the amount requested is less than the current balance amount. It also has to be able to handle deposits. The image below is a visual representation of what an Account object could be. Well, at least a simplification of that.
There are some guidelines on how to identify objects and methods in requirements: "nouns" are good candidates for "objects", while "verbs" are good candidates for "methods". That's only a guideline, which means they are "good defaults", but not hard rules.
Reification
OOP is really good at modeling abstract concepts. Things that are not tangible, but we can pretend they exist in the reality we're trying to build inside our software. They are objects (or "little beings"). The term Reification means to treat immaterial things as they were material. We use that all the time when we're writing software, especially in Object-Oriented Software. Our Account model is one example of reification.
It happens to fit the "noun" and "verb" guideline, because that makes sense in our context so far. Here's a simple example of a deposit:
class Account extends Model{ public function deposit(int $amountInCents) { DB::transaction(function () { $this->increment('balance_cents', $amountInCents); }); }}Notes on Active Record
The code examples are done in a Laravel context. I'm lucky enough to happen to own the databases I work with, so I don't consider that an outer layer of my apps (see this), which allows me to fully use the tools at hand, such as the Eloquent ORM - an Active Record implementation for the non-Laravel folks reading this. That's why I have database calls in the model. Not all classes in my domain model are Active Record models, though (see this). I recommend experimenting with different approaches so you can make up your own mind about these things. I'm just showing an alternative that I happen to like.
But that's not the end of the story. Sometimes, you need to break these "rules", depending on your use case. For instance, you might have to keep track of every transaction happening to an Account. You could try to model this around the relevant domain methods, maybe using events and listeners. That could work. However let's say you have to be able to schedule a transfer or an invoice payment, or even cancel these if they are not due yet. If you listen closely, you can almost hear the system asking for something.
Knowing only its balance isn't that useful when you think of an Account. You have 100k dollars on it, sure, but how did it get there? These are the kind of things we should be able to know, don't you think? Also, if you model everything around Account, it tends to grow to a point of becoming God objects.
This is where people turn to other approaches like Event Sourcing. And that could be the answer, as the primary example for it is a banking system. But there is an Object-Oriented way to model this problem.
The trick is realizing our context has changed. Now, we need to focus on the transactions happening to the account (only "withdraw" and "deposit" for now). They deserve the main stage in our application. We will promote these operations to objects, calling them transactions. And those objects can have their own state. The public API of the account wouldn't change, only its internals.
Instead of simply manipulating the balance state, the Account object will create instances of each transaction and also keep track of them internally. But that's not all. Each transaction has a different effect on the account's balance. A deposit will increment it, while a withdraw will decrement it. This serves as an example for another important concept of Object-Oriented Programming: Polymorphism.
Polymorphism
Polymorphism means: multiple forms. The idea is that I can build different implementations that conform to the same API (interface, protocol, or duck test). This fits exactly our definition of the different transactions. They are all transactions, but with different application on the Account. When modeling this with ActiveRecord models, we could have the following:
- An Account (AR model) holds a sorted list of all transactions
- A Transaction would be an AR model and would have a polymorphic relationship called "transactionable"
- Each different transaction would conform to this "transactionable" behavior
The trick would be to have the Account model never touching its balance directly. The balance field would almost serve as a cached value of the result of every applied Transaction of that account. The Account would then pass itself down to the Transaction expecting the transaction to update the balance. The Transaction, internally, would then delegate that task to each transactionable and they could update the balance. It sounds more complicated than it actually is, here's the deposit example:
use Illuminate\Database\Eloquent\Model; class Account extends Model{ public function transactions() { return $this->hasMany(Transaction::class)->latest(); } public function deposit(int $amountInCents) { DB::transaction(function () use ($amountInCents) { $transaction = $this->transactions()->create([ 'transactionable' => Deposit::create([ 'amount_cents' => $amountInCents, ]), ]); $transaction->apply($this); }); }} class Transaction extends Model{ public function transactionable() { return $this->morphTo(); } public function setTransactionableAttribute($transactionable) { $this->transactionable()->associate($transactionable); } public function apply(Account $account) { $this->transactionable->apply($account); }} class Deposit extends Model{ public function apply(Account $account) { $account->increment('balance_cents', $this->amount_cents); }}As you can see, the public API for the $account->deposit(100_00) behavior didn't change.
This same idea can be ported to other domains as well. For instance, if you have a document model in a collaborative text editing context, you cannot rely on having a single content text field holding the current state of the Document's content. You would need to apply a similar idea and keep track of each Operation Transformation happening to the document instead.
Another example could be an PaaS app. You have provisioned servers and you can deploy on them. With only this short description one could model it as $server->deploy(string $commitHash). But what if the user can cancel a deployment? Or rollback to a previous deployment? That change in requirements should trigger your curiosity to at least experiment promoting the deploy to its own Deployment object or something similar.
I first saw this idea presented by Adam Wathan on his Pushing Polymorphism to the Database article and conference talk. And I also found references in the book Smalltalk, Objects, and Design, as well as on a recent Rails PR done by DHH introducing delegated types. I find it really powerful and quite versatile, but I don't see that many people talking about it, so that's why I found it relevant to mention here.
Before we wrap up this Reification tangent, there's one more example I wanted to mention. When you have two entities collaborating on a behavior and the logic doesn't quite fit one or the other. Or the behavior could perfectly fit either of these entities. For instance, let's say you have a Student and a Course model and you want to keep track of their presence and grade (assuming we only have a single presence valeu that can either be present | absent and single grade value ranging from 0 to 10). Where do we store this data?
It should feel like it doesn't belong in the Course, nor in the Student records. It almost feels like the solution to this problem could be to give up on OOP entirely and use a function that you could pass both objects to. Or we could maybe store that value as a pivot field in a joint table. Instead, if we reify this problem, we could promote the Student/Course relationship to an Object called StudentCourse. That would make the perfect place to store the grade and presence. These are examples of reification.
Abstractions as Simplifications
I've talked about this idea before. I have a feeling that some people see abstractions as convoluted architectural decisions and as a synonym for "many layers", but that's not what I understand of abstractions. They are really simplifications.
Alan Kay has a good presentation on the subject and he states that we achieve simplicity when we find a more sophisticated building block for our theories. A model that better fits our domain and things "just make sense".
The example of Kepler and the elliptical orbit theory that Kay uses is really good (read more about it here). At that time, there was a religious belief that planets moved in "perfect circles", where the Sun was orbiting the Earth while other objects were orbiting the Sun.
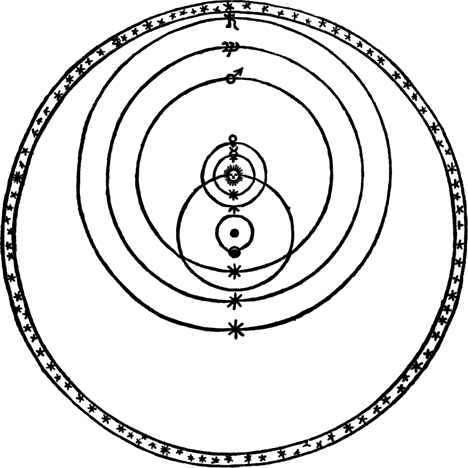
Source: NASA's Earth Observatory (link)
That didn't quite make sense because objects seemed to be in different positions depending on the day (among other problems), so they built a different theory where the orbits were still "perfect circles" but the objects were not going round, but instead moving in a way that at a macro level also built another "perfect circle", something like this:
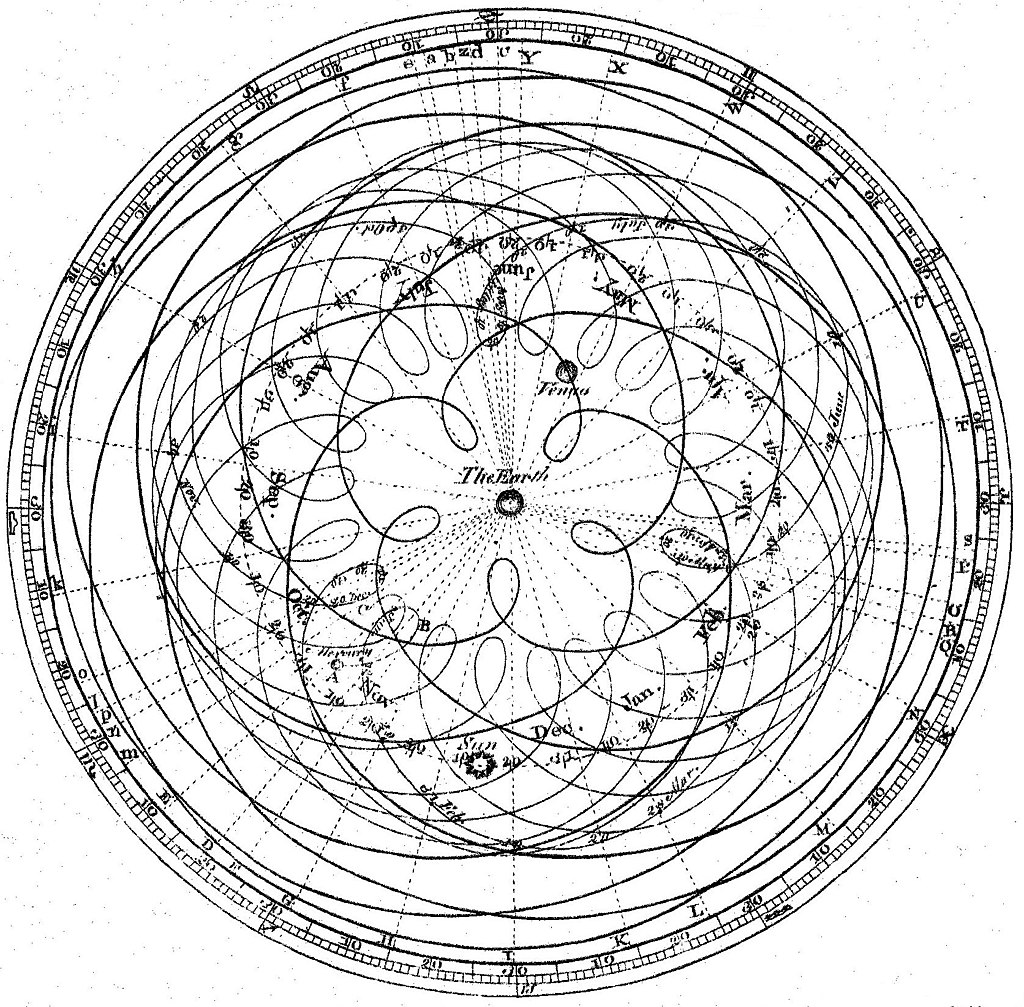
Source: Wikipedia page on "Deferent and epicycle" (link)
Kepler had this belief too, but after struggling to explain some of the evidences about the movements of objects, he then abandoned the idea of "perfect circle" and suggested that the orbits were actually elliptical and around the Sun - not the Earth, simplifying the model quite a lot (read this to know more about this).

Source: Wikipedia page on "Kepler's laws of planetary motion" (link)
His observation was one of the pillars of Newton's law of universal gravitation. Which later led to Einstein's theory of relativity.
The point is: the right level of abstraction often simplifies our models. Things "just makes sense" in a way that it's easier to understand than the alternatives. And it's an iterative process.
Objects In The Large
So far we've talked about promoting methods to objects. But that is not quite the same as having Actions or UseCases as classes, right? That's more about having domain models at the right level of abstraction.
In the seminar, Kay also states that objects are not enough when working on large scale systems. That's mainly because of the complexity of the systems. We want to be able to shut down, replace, and bring up parts of the system - or "modules", without affecting the entire system. Or, say, you could benefit from implementing a specific part of your system in another language because of performance reasons or a more accurate floating-point calculation.
The problem here is that we are trying to shield the messages from the outside World (our protocol). Even with all the protections that OOP provides (such as encapsulation), it doesn't guarantee that you have a good architecture.
Kay even mentions that there were 2 phases when learning Smalltalk and OOP:
- On the first phase you're delighted with it. You think it's the silver bullet you've always been looking for;
- The second phase is delusional, because you see first hand that Smalltalk doesn't scale.
One way to make OOP work on such large scale systems is to create a class for the "goals" we want to guarantee in the application. It looks like a type in a typed language, but it's not a data structure. The focus should be on the goal, not on the type. Kay uses an example of a "Print" class, where each instance of this class is a message (instead of method calls in the object). These look like what we see as Actions or Use Cases these days.
See, in Smalltalk, everything is an object. They take this very seriously. Even messages are objects internally. The difference between a message and a function call is that the message contains the receiver. In IBM Smalltalk, for instance, they even have different classes for messages with and without the receiver (look for "Message and DirectedMessage" in the manual). So when we send a message to the object, we're essentially telling the runtime to do a method dispatch on the receiver of that message. You can see that as the default goal of a message. What Kay seems to be suggesting is that we can create our own goals for our own systems. We'll explore this in a bit.
Another problem of OOP Kay describes is that we tend to worry too much about the state our objects hold and neglect the control flow (who sends the message to whom). That ends up becoming a mess. An Object sends a message to another Object, which sends a message to a bunch of other Objects, and those send messages to even more objects. Good luck trying to understand this system.
Kay suggests what resembles a Pub/Sub approach. They were exploring a more declarative approach in Smalltalk. Instead of sending messages directly to each other, Objects would declare to the system which messages they are interested in (subscribing). Messages would then "broadcast" to the system (publishing). If you have done any UI work, this should feel familiar to you, because it looks like event listeners in JavaScript.
This declarative aspect is fascinating, and it's present in some Functional Programming languages too (if you want to see where the ideas OOP blends with FP, watch this talk by Anjana Vakil called "Oops! OOP's not what I thought").
Messages as Objects
Let's explore what Kay suggests in the Seminar for a second: the idea of implementing our own goals in the system.
In our example, we could have a Deposit action in our application. It could be totally independent of the outside World (transport mechanisms - I treat the database as an "inside" part of my apps), something like:
namespace App\Actions; use App\Models\Account;use App\Models\Transactions\Deposit as DepositModel;use Illuminate\Support\Facades\DB; class Deposit{ public function handle(Account $account, int $amountInCents): void { DB::transaction(function () use ($account, $amountInCents) { $transaction = $account->transactions()->create([ 'transactionable' => DepositModel::create([ 'amount_cents' => $amountInCents, ]), ]); $transaction->apply($account); }); }}With this in place, our Account model doesn't need the deposit method anymore. This is the decision I have mixed feelings about, to be honest. Maybe it's fine since we promoted the Deposit message to an object as well? However, we could also implement a Facade method in the Account that would delegate to this action:
use App\Actions\Deposit as DepositAction; class Account extends Model{ public function deposit(int $amountInCents) { (new DepositAction())->handle($this, $amountInCents); }}This way we would keep the behavior separate in its own object, and still maintain an easy to consume API on the Account model. That's what I feel more comfortable with these days.
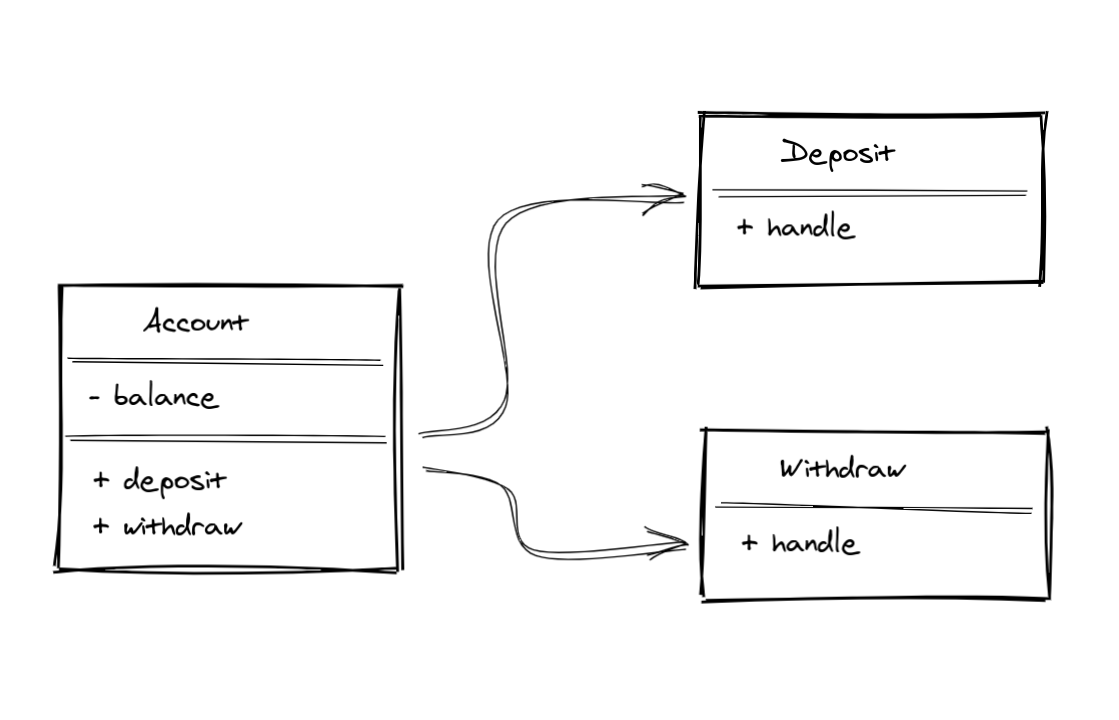
One "downside" of this approach is that every dependency of the Deposit message would have to be part of the method signature of the Facade method as well. Not a big deal, and most of the time it makes sense. Say you're modelling a PayInvoice action, you would most certainly need to pass a PaymentProvider dependency to the $invoice->pay($provider, $amount) facade method (or a factory).
Also, we could use Laravel's Job abstraction here, as jobs can be both synchronous or asynchronous. This way, we would benefit from that aspect as well (dispatching a background job as a "message" to do the task asynchronously).
Conclusion
My intent with this article is mainly to share and hear back from other people what they think of this all. I'm not trying to convince you of anything. I'm making peace with this idea of having actions for behavior (as messages) myself. It sometimes feels like "procedures" where we're invoking logic by name. I'm not sure if I would use it for every bit of logic in my applications, but I think I like it when combined with Facade methods in the models.
I also found some cool design patterns that I don't see being referenced a lot. I'll blog about them soon.
Let me know what you think about this. Either tonysm@hey.com to me, tweet, or write a response article and share it with me.
P.S.: I only now found this great talk from Anjana Vakil called "Programming Across Paradigms" which I highly recommend.
P.S. 2: Some images here were created using Excalidraw
P.S. 3: As I was reading the book "Smalltalk Best Practice Patterns" I found out this was a known pattern in the Smalltalk days called Method Object. Kent Beck even states there that he was not going to include the pattern in the book, but it was really helpful once so he added it. He mentions this is useful usually in the "core" of the app when you need to interact with a bunch of objects and have temporary variables around. Another reference that suggests this should not be used for everything.
Criticism on OOP
While I was reading the book Smalltalk, Objects, and Design I found out that Dijkstra doesn't seem to like OOP (see this quora question and responses). He advocated against the use of metaphors and analogies in software (referenced, but I haven't read it fully myself), and in favor of a more "formal" and mathematical way of building software (in terms of formal thinking), as he coined the term "structured programming". But the book also mentions there is research on invention and creativity (referenced, but I haven't read it myself) that suggests that imagery fuels the creative process, not formal thinking. I found this all very entertaining to research.
Relevant References
- Alan Kay's Seminar on OOP (YouTube)
- Barbara Liskov TEDxMIT talk: How Data Abstraction changed Computing forever (YouTube)
- Smalltalk, Objects, and Design (Book)
- Laravel Beyond CRUD: Actions (Blog post)
- A Conversation with Badri Janakiraman about Hexagonal Rails (Video)
- The Clean Architecture (Blog post)
- Alan Kay's 2015 talk: Alan Kay, 2015: Power of Simplicity (YouTube)
- Joe Armstrong's (RIP) message in the Elixir Forum (Link)
- Joe Armstrong interviews Alan Kay (YouTube)
- Adam Wathan's "Pushing Polymorphism to the Database" (Blog post and Talk)
- DHH's Rails Pull Request Introducing Delegated Types (Link)
- Anjana Vakil talk called "Oops! OOP's not what I thought" (YouTube)
- Anjana Vakil talk called "Programming Across Paradigms" (YouTube)
You can use Cloud Native Buildpacks to create Docker Images without having to write a single line in a Dockerfile.
You will need:
# From the root folder of your Laravel application, run the# `pack build` to create your Dockerfile using Heroku's builder.pack build \ --builder heroku/buildpacks \ --buildpack heroku/nodejs \ --buildpack heroku/php \ tonysm/buildpack-app # Run your Docker Image.docker run \ --rm -d \ --name=buildpack-example \ -p 8000:80 \ -e PORT=80 \ tonysm/buildpack-app # Now you can open http://localhost:8000 on your browser. # To stop the container, run:docker stop buildpack-exampleContinue reading if you want to understand what's going on.
Containers
Containers might feel intimidating at a first sight, but it really isn't that complicated. First, containers are lies. The term "container" refers to a set of features from the Linux Kernel.
Source: https://en.wikipedia.org/wiki/Docker_(software)
A container is another way to package your application for distribution. It's kinda like when we used to zip our applications, send to a server, unzip it there, and run (*cough, cough* lambda, *cough, cough*). It's like a zip file or a tarball, but one where you can also add instructions on how to run the application.
All this fuss over fetching a tarball and executing the contents.
— Kelsey Hightower (@kelseyhightower) August 31, 2016
Docker Images
Docker is another umbrella term for a set of tools. In fact, Docker has so many goodies these days that Kubernetes recently deprecated using it to run containers. Don't worry, Docker isn't going away. Kubernetes is just not going to use it to run containers. Docker these days has a lot of things built-in, much more than what Kubernetes needs to run a container. That's the only reason they are favoring other container runtimes.
For building container images, Docker is still King. There are many ways we can create Docker images. You could spin-up a container using an official Ubuntu image, run your commands inside the container and then commit your changes to create your image manually. Or you could write a Dockerfile, like so:
FROM ubuntu:20.04 LABEL maintainer="Taylor Otwell" ARG WWWGROUP WORKDIR /var/www/html ENV DEBIAN_FRONTEND noninteractiveENV TZ=UTC RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone RUN apt-get update \ && apt-get install -y gnupg gosu curl ca-certificates zip unzip git supervisor sqlite3 libcap2-bin libpng-dev python2 \ && mkdir -p ~/.gnupg \ && chmod 600 ~/.gnupg \ && echo "disable-ipv6" >> ~/.gnupg/dirmngr.conf \ && apt-key adv --homedir ~/.gnupg --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys E5267A6C \ && apt-key adv --homedir ~/.gnupg --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys C300EE8C \ && echo "deb http://ppa.launchpad.net/ondrej/php/ubuntu focal main" > /etc/apt/sources.list.d/ppa_ondrej_php.list \ && apt-get update \ && apt-get install -y php8.0-cli php8.0-dev \ php8.0-pgsql php8.0-sqlite3 php8.0-gd \ php8.0-curl php8.0-memcached \ php8.0-imap php8.0-mysql php8.0-mbstring \ php8.0-xml php8.0-zip php8.0-bcmath php8.0-soap \ php8.0-intl php8.0-readline \ php8.0-msgpack php8.0-igbinary php8.0-ldap \ php8.0-redis \ && php -r "readfile('http://getcomposer.org/installer');" | php -- --install-dir=/usr/bin/ --filename=composer \ && curl -sL https://deb.nodesource.com/setup_15.x | bash - \ && apt-get install -y nodejs \ && apt-get install -y mysql-client \ && apt-get -y autoremove \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* RUN setcap "cap_net_bind_service=+ep" /usr/bin/php8.0 RUN groupadd --force -g $WWWGROUP sailRUN useradd -ms /bin/bash --no-user-group -g $WWWGROUP -u 1337 sail COPY start-container /usr/local/bin/start-containerCOPY supervisord.conf /etc/supervisor/conf.d/supervisord.confCOPY php.ini /etc/php/8.0/cli/conf.d/99-sail.iniRUN chmod +x /usr/local/bin/start-container EXPOSE 8000 ENTRYPOINT ["start-container"]This example was taken from Laravel Sail. It installs a bunch of dependencies the application needs to run, some instructions to the image users (us), such as the exposing port, and some instructions for the container runtime, such as the entrypoint that will receive commands for this container.
That's the common way. There is another way, though. What if I told you we don't need to write a single line of a Dockerfile to create a Docker Image? Enters Cloud Native Buildpacks.
Cloud Native Buildpacks
You might have used Heroku already (or at least heard of it). Heroku is a platform where you can deploy your applications to. Its unit of work are called "Dynos", and you can deploy to Heroku using a regular git push command. Turns out Heroku uses the container model. When you do a git push they will essentially package up your application source in a container for you. The key-point is that you don't even need to know that. Well, most of the time.
They are able to do that using buildpacks. Buildpacks detect which engines your application use and is able to "guess" how to run your application. Let's create a Docker Image without a Dockerfile. You need to install the pack CLI tool. Follow their instructions to get it installed on your machine. You'll also need Docker, of course.
Now, let's create a Laravel application and try using Heroku's builder:
# Create a Laravel app.laravel new --jet --stack=livewire --teams example-app # Create the Docker image.pack build --builder heroku/buildpacks tonysm/buildpack-appIf you look at the output, you will see how the Heroku builder tries a bunch of buildpacks until one of them returns positive for the detection. The detection rules might be as simple as checking if you have a package.json file for the NodeJS buildpack, for instace.
And... that's it, actually. Well, kind of. Let's try running this container image locally:
docker run \ --rm -d \ --name=buildpack-example \ -p 8000:80 \ -e PORT=80 \ tonysm/buildpack-appIf you try to open http://localhost:8000 in your browser, it won't quite work yet. We need one more thing to make it work: a Procfile. This file will be used to describe our process model. Let's create it:
web: heroku-php-apache2 public/Here we're instructing the builder that we want a process called "web" and this process will run the heroku-php-apache2 public/ command as its entrypoint. We mainly needed this file now to tell the heroku-php-apache2 binary to serve the public/ folder.
We could have as many processes in our Procfile as we need. We'll explore that soon. For now, let's try running our app again. We need to stop the running container first.
docker stop buildpack-exampleSince we used the --rm option when running the container, it's completely gone now. We can now build it again and try to run it:
pack build --builder heroku/buildpacks tonysm/buildpack-app docker run \ --rm -d \ --name=buildpack-example \ -p 8000:80 \ -e PORT=80 \ tonysm/buildpack-appNow, let's try it on the browser again and... voilà!
Looks like we're done, but if you try to load the login or the register routes, you will see a "Mix manifest does not exist" error. That's right. The builder didn't install and compile our dependencies for us. Let's do that. We have been relying on the "auto-detection" feature of Heroku's builder, but we can help it. We can even combine different buildpacks to create our image. Let's instruct it to use the NodeJS buildpack and the PHP buildpack after that.
Before we do that, we need to instruct the NodeJS buildpack to also compile our assets for us. The NodeJS buildpack will look for an run a build NPM script on your package.json file (if you have a non-related build script already, you can add a heroku-build script, which will be used instead). Add the following line to it:
{ "scripts": { "prod": "...", "build": "npm run prod" }}Now we can build our image using both buildpacks:
pack build \ --builder heroku/buildpacks \ --buildpack heroku/nodejs \ --buildpack heroku/php \ tonysm/buildpack-app docker run \ --rm -d \ --name=buildpack-example \ -p 8000:80 \ -e PORT=80 \ tonysm/buildpack-appNow, if you try to access the login form, you will no longer see the "Mix manifest missing" error.
The form doesn't work as is. That's because we would need to run a database and configure the container to talk to that DB, but that's not the scope of this article.
Multiple Processes
As I mentioned, we can have multiple processes described in our Procfile, as many as our application needs. Let's create a console command in Laravel and add another process entry to our process model. If you want to know more about this process model, I recommend checking out this article.
First, edit your routes/console.php file and add the following lines:
Artisan::command('test:proc', function () { $run = true; pcntl_async_signals(true); pcntl_signal(SIGTERM, function () use (&$run) { $run = false; $this->comment('Shutting down...'); }); while ($run) { $this->comment('Testing'); sleep(1); } $this->comment('Bye!');})->purpose('Displays a message to test the process model.');Second, edit the Procfile and add another process called worker, like so:
web: heroku-php-apache2 public/worker: php artisan test:procLastly, let's build this image again:
pack build \ --builder heroku/buildpacks \ --buildpack heroku/nodejs \ --buildpack heroku/php \ tonysm/buildpack-appNow, the builder will create one binary file you can use as the entrypoint when running the command. You can see the default entrypoint by inspecting the image:
docker image inspect tonysm/buildpack-app # ... "Entrypoint": [ "/cnb/process/web" ],# ...I think the first process in your Procfile will be used as the default entrypoint. If you inspect the container, you will see the other binaries with the names we gave in the Procfile also living in the /cnb/process/ folder. To run our test:proc console command, we need to point the worker binary in that folder as the entrypoint, like so:
docker run \ --rm -d \ --name=buildpack-example-worker \ --entrypoint /cnb/process/worker \ tonysm/buildpack-appThis will get your worker running in background, now you can read its logs by running:
docker logs -f buildpack-example-workerNice! If you don't specify the entrypoint, your container will start the first process defined on your Procfile.
To stop the worker, run:
docker stop buildpack-example-workerConclusion
I wanted to show you how we can make use of Cloud Native Buildpacks to build our Docker images without having to write a Dockerfile. Hope this was useful.
]]>To me, the best thing about such boilerplate is how the teams are set up. People assume that the resources they create in a web application are "isolated" (unless specified otherwise). That "trait" is called multi-tenancy. It comes in different sizes and shapes.
The most common implementation of multi-tenancy is isolating by a "scope key". Something that uniquely identifies the resource owner. It's easy to assume that whenever we create something "we" are the "scope", but very shortly we'll want to share these resources with others.
You can model that collaboration in different ways. With these boilerplates, I would assign these resources to the user's current team. Billing would also be handled at the team level. Collaborators would be added to the team with different roles. Everything gets so much simpler this way.
What about "the regular user" that is not part of an organization or a team? Do they need to create their own teams? Short answer, yes. However, there is no "extra process", the sign up flow creates your "personal team" as soon as you sign up. You set up the billing information on your personal team, and you should be able to create your own resources, which will get assigned to your personal team.
If, at any point in time, you want to invite a collaborator, you can just do that. Personal Teams are Teams after all. Many applications have limitations on how many collaborators you can have in a team, which I'm not a fan of as this approach creates some friction on the collaborative aspects of your applications. Some people call this "Collaboration Tax".
Anyways, with Jetstream we get a lot of things out-of-the-box such as a very flexible and simple way to organize our application's users and resources in "teams". Much simpler than trying to have different, special flows and multiple types of resource owners (users or teams) or multiple ways to collaborate on your applications.
You can call teams whatever you want on your applications, and you can have other levels of granularity to organize users, such as "groups", inside your teams. You just have to implement it yourself.
]]>Pretty neat to see the Rails parallel test runner peg all cores and hyperthreads on my 8-core iMac. 10,000 assertions across 2,000 tests completing in 1 minute, 29 seconds. No fancy magic! All hitting the Dockerized DB. (This is for a 0.8 test ratio on an app that's 25KLOC.) pic.twitter.com/59xCf1lMp6
— DHH (@dhh) October 29, 2020Ever since I saw that Rails 6 was shipping with a parallel test runner I got curious if we couldn't have something like this for Laravel and PHPUnit.
I knew there was Paratest, which allows running your PHPUnit tests in parallel without much trouble. By default, it separates test classes in groups and run each group in a different process.
That was awesome, but I faced an issue. My feature tests hit the database and, since each process will try to migrate the database, instead of getting a speed boost, I got a lot of errors.
So I started tinkering with a package to make this experience easier. After exploring Rails itself, I noticed that each process creates its own database, which makes sense.
At this point I had two options:
- I could swap the RefreshDatabase trait for the DatabaseTransaction one and manage the test database migration myself (probably would be the easiest route); or
- I coul find a way to programatically create one database for each test process.
I decided to follow the second route, because I'd like to avoid having to remember to run the migrations before running the tests every time I pulled some changes. This turned out to be possible. Paratest, by default, creates an environment variable called TEST_TOKEN and each process gets assigned a unique one (unique for the test run).
So I implemented some artisan commands, such as the db:create one, and also a custom test runner that would create the database before the process runs the test. Essentially, this ends up mimicking the same behavior from Rails: each process creates its own database, which is migrated once per process and each test runs in a transaction, which is rolled back after each test.
Here's the project on GitHub, I've recently upgraded it to Laravel 8. It's already available on Packagist, so you can already pull it locally and try to use it yourself.
To be honest, I don't need such feature because my tests tend to run quite fast. But something like this might be handy on bigger projects or in a CI environment.
]]>I was working on a piece of UI that had a requirement for Infinite Scrolling. So I went ahead to try to implement that using Inertia. I tried a couple of ways, so I figured it would be fun to document my attempts and what I ended up using, as well as some foggy ideas.
My attempts were:
- Load more messages using
Inertia.visit; and - Load more messages using
axios.getinstead of making an Inertia visit.
Either way, I had to fix something first: we need a local state in our page component to keep the current messages shown, otherwise Inertia will replace our props with the items on the new page. Let me show you want I mean.
Local State Management with Inertia.js
The issue with Infinite Scrolling and Inertia is that we usually pass data down to your components from the controller and using it as props on the page component:
class ChatRoomsController extends Controller{ public function show(ChatRoom $chatRoom) { $messages = $chatRoom->messages() ->latest() ->with(['user']) ->paginate(); return Inertia\Inertia::render('ChatRooms/Show', [ 'chatRoom' => $chatRoom, 'messages' => $messages, ]); }}In the page component, we would have something like this:
<template> <div> <button @click="loadMore">Load more...</button> <ul> <li v-for="message in messages.data" :key="message.id"> {{ message.user.name }} said: {{ message.content }} </li> </ul> </div></template> <script> export default { props: { chatRoom: Object, messages: Object, }, methods: { loadMore() { // Get more messages. }, }, }</script>If we make another Inertia visit to the GET /chat-rooms/{chatRoom} endpoint passing a ?page=2 query string, it would work in the backend, the query would skip the first items and give us the second "page" of messages, but Inertia would replace our messages prop, therefore we would lose track of the messages previously shown.
Luckily, we can fix that relatively easy by introducing a bit of local state, so our page component would become something like this:
<template> <div>- <button @click="loadMore">Load more...</button>+ <button @click="loadMore" :disabled="loadingMore">Load more...</button> <ul>- <li v-for="message in messages.data" :key="message.id">+ <li v-for="message in localMessages" :key="message.id"> {{ message.user.name }} said: {{ message.content }} </li> </ul> </div></template> <script> export default { props: { chatRoom: Object, messages: Object, },+ data () {+ return {+ loadingMore: false,+ localMessages: this.messages.data,+ pagination: this.messages,+ };+ }, methods: { loadMore() { // Get more messages. }, }, }</script>Alright, now we are ready to explore the first attempt.
Load more messages using Inertia.visit
To implement the loadMore methods in the ChatRooms/Show.vue page component, we need to make another Inertia visit:
<script> export default { // The rest of the component... methods: { loadMore() { if (this.loadingMore) return; this.loadingMore = true; this.$inertia .visit( `/chat-rooms/${this.chatRoom.id}?page=${this.pagination.current_page + 1}`, { preserveState: true } ) .then(() => { // Prepending the old messages to the list. this.localMessages = [ ...this.messages.data, ...this.localMessages, ]); // Update our pagination meta information. this.pagination = this.messages; }) .finally(() => this.loadingMore = false); }, }, }</script>So, essentially, we are making another Inertia visit and that will get to the ChatRoomsController@show controller, load the second page of messages and return to Inertia, so it can then re-render the page component with the new props. If we had more props here, we could tell it to only care about the messages prop by using Partial Reloads and Lazy Evaluation, but let's keep it simple for now.
What is impontant to note here is that we are telling Inertia to preserve the current component's state by passing { preserveState: true } to the visit, otherwise it would force a new component (with a new state) to render, losing our localMessages data.
Although this approach works, when we load more items into the page, since this is a new Inertia visit, we get a new page added to your browser history stack. Which means that if we hit the back button of our browser after loading a couple pages, you will go back to the previous page, but also losing your local state, because Inertia will only restore the previous props.
Also, with this approach, if we hit refresh on our browser, we will only see the current page's messages, which means your local state was also lost and the backend is making use of the ?page=3 param in the query string.
We could solve this problem by storing the messages on localStorage keyed by the chat room ID or something like that, but I think that would get even more trickier.
Let's explore the second approach.
Loading more messages using axios.get
We could make this one work by using axios directly, instead of making an Inertia.visit. Let me show you what I mean:
<script> export default { // The rest of the component... methods: { loadMore() { if (this.loadingMore) return; this.loadingMore = true; - this.$inertia- .visit(- `/chat-rooms/${this.chatRoom.id}?page=${this.pagination.current_page + 1}`,- { preserveState: true }- )+ axios.get(`/chat-rooms/${this.chatRoom.id}?page=${this.pagination.current_page + 1}`) - .then(() => {+ .then(({ data }) => { // Prepending the old messages to the list. this.localMessages = [- ...this.messages.data,+ ...data.data, ...this.localMessages, ]); // Update our pagination meta information.- this.pagination = this.messages;+ this.pagination = data; }) .finally(() => this.loadingMore = false); }, }, }</script>We are not done yet. Now we are making an AJAX request to the GET /chat-rooms/{chatRoom} route, which returns an Inertia response, but we don't want that. Since this is not an Inertia visit, it would treat the request as a "first render" of Inertia, giving us the HTML used in the first page render. We could change the backend to treat AJAX requests differently:
class ChatRoomsController extends Controller{ public function show(ChatRoom $chatRoom) { $messages = $chatRoom->messages() ->latest() ->with(['user']) ->paginate();++ if (request()->wantsJson()) {+ return $messages;+ }+ return Inertia\Inertia::render('ChatRooms/Show', [ 'chatRoom' => $chatRoom, 'messages' => $messages, ]); }}Now, if you try to load more messages again, it should work as expected. However, something smells here. Our ChatRoomsController@show action is returning messages instead of the chatRoom resource expected. Let's fix that.
Creating a new Messages resource
We can create another route for the Chat Room's Messages, like:
class ChatRoomMessagesController extends Controller{ public function index(ChatRoom $chatRoom) { return $chatRoom->messages() ->latest() ->with(['user']) ->paginate(); }}And we can change our loadMore method to get more messages from this new endpoint instead of the current ChatRoom show:
<script> export default { methods: { loadMore () { if (this.loadingMore) return; - axios.get(`/chat-rooms/${this.chatRoom.id}?page=${this.pagination.current_page + 1}`)+ axios.get(`/chat-rooms/${this.chatRoom.id}/messages?page=${this.pagination.current_page + 1}`) .then(({ data }) => { this.localMessages = [ ...data.data, ...this.localMessages, ]; this.pagination = data; }) .finally(() => this.loadingMore = false); } }, }</script>Now, we have a dedicated endpoint for the chat room's messages. I think I like that more. There's a bit of duplication here, though. Both actions know how to get paginated messages of a chat room. Since these were the only two places where this happens, I'm fine with it. Otherwise, we could create a query object or something like that and place this logic there.
I also simplified the query side a bit. In a chat, we would have the show the latest messages but in reverse order, so the very last message would appear at the bottom of the page, not at the top. We could solve it but reversing the collection inside our paginator, like this:
use Illuminate\Pagination\LengthAwarePaginator; $messages = tap($chatRoom->messages() ->latest() ->with(['user']) ->paginate(50), function (LengthAwarePaginator $paginator) { $paginator->setCollection( $paginator->getCollection()->reverse()->values() ); });And in this case, I think I would prefer to place it in a query object somewhere and/or call it from my ChatRoom model like this:
$messages = $chatRoom->getPaginatedMessages();Anyways, I wanted to keep the example simple. Another way to fix this would be to create a computed prop in the page component that sorts the messages by timestamp. Either way is fine by me.
Conclusion
As you can see, I ended up using a simple axios.get and prepending the new messages to my localMessages state in the page component. This solution isn't perfect, though. If you change rooms and go back in history, you are still left with only the latest messages of the room (you lost all the pages that were loaded later). But it's a lot better than making via Inertia.visit, for this use case.
It got me thinking if there couldn't be a way to tell Inertia to "merge" props with the current props instead of replacing it. Something like this:
this.$inertia.visit( '...', { preserveState: true, only: ['messages'], mergeProps: { messages: 'prepend' }, })This would allow us to keep the current page of messages from the first visit and merge new messages by prepending it. Could also be useful when we are creating a new message, something like:
class ChatRoomMessagesController extends Controller{ public function store(ChatRoom $chatRoom) { $message = $chatRoom->createMessage( request()->user(), request()->input('message.content') ); return Inertia\Inertia::appendProps([ 'messages' => [$message], ]); }}Which would add the new message to the end of the current list of messages in the component's props.
Also, it got me thinking if there shouldn't be a way to make inertia visits "transparently". And with that I mean without affecting the browser history (skip push state) and all that.
I don't know, maybe all this would make things more complicated. For now, I would say keep it simple and use local state + axios.get when you need something like Infinite Scrolling.
Anyways, I hope you enjoyed the ride.
]]>Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.
This is not advice against optimization. The gist of this is that we shouldn't spend time blindly optimizing code that in theory can be faster. We should always be backed by data.
The numbers seem arbitrary, though. Where did 97% and 3% come from? I haven't read Knuth's books yet, so I really don't know. In practice, I think it's safe to assume Pareto's principle: 80% of your application performance issues come from 20% of the code.
When we're optimizing applications, it's important to understand "the grand scheme" of things. That little micro-optimization that made it 80% faster might not make any difference at all. How much of the total work is spent doing that in the first place?
That's not to say that micro-optimizations are bad. But if the application is spending 4ms of the total time doing that thing we optimized, making it 10% faster will only make it run in 3.6ms instead of 4ms. If the total response time is 300ms, saving 0.4ms doesn't seem like a lot, does it?
You can't improve what you don't measure
Benchmarking only tells part of the story. It's only able to tell the micro-level of the optimization. We need to know the whole story. Or most of it (80%?). When we profile that change in a real-world scenario, we don't get much out of that micro-optimization.
When it comes to code optimization, it should always be backed by benchmarks and profiling.
- Benchmark can give us how much faster code A is compared to code B;
- Profiling can give us how much time our application spends running code A for an entire feature (or code path).
The first thing we need to do when we put an application in production is configuring a good instrumentation tool. Application Performance Management tools (aka. APMs) can give us the profiling information. Tools such as Blackfire, NewRelic, or Elastic APM seem like good choices. They can tell us where the code is spending more time at.
Optimization Fallacies
We sometimes take other people's advice blindly. For sure N+1 queries are always bad, right? Well, not always. Basecamp uses a caching technique called "Russian Doll Caching" a lot. The idea consists of caching entire partials on the view layer so that the lazily-loaded relationships are not even used in the first place. This, in combination with model touching (if we have a Post hasMany Comment relationship set where Comment changes will touch on its Post's timestamp) enables N+1 queries as a feature instead of a bug.
Note: My feeling is that we underuse caching in Laravel. Not sure why, but stuff like clearing the cache is common in deployment scripts. Caching in the view layer isn't common either (IME). And eager-loading at the controller level to avoid N+1 queries seems to be the de facto way of doing things these days. Basecamp seems to heavily make use of caching and N+1 queries without much trouble.
The point is: we need to understand the full picture of things. The "grand scheme". We need profiling data in order to make any relevant optimizations on our applications. Rewriting applications in a faster, compiled languages won't necessarily make it that much faster or cheaper to run.
]]>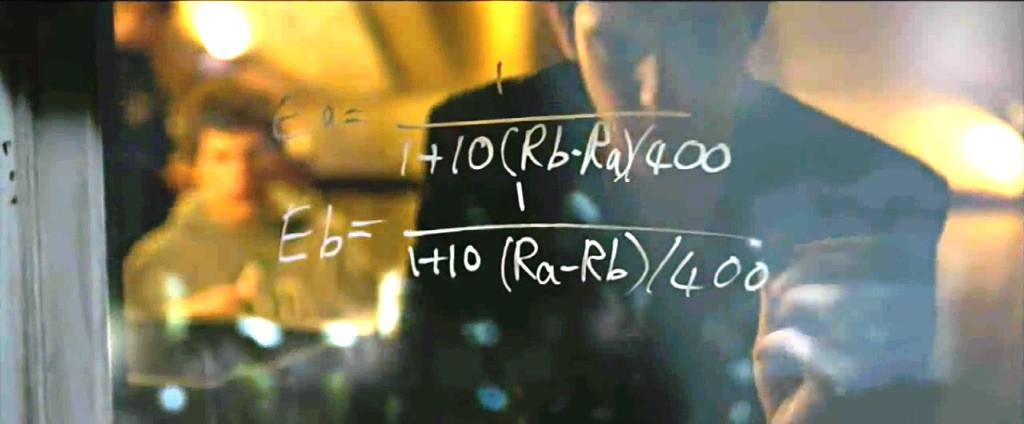
You might remember this scene from the movie The Social Network. That formula indicates they used the Elo Rating Systems in the "face match" app before Facebook was a thing. Zuckerberg and the others used it in an "evil" game context where we compare one person's appearance against another person's appearance, but that's not the point of this article.
Elo Rating Systems can be used when you have any kind of "match" between two players (or teams). If you have that kind of system at play, your first "naive" implementation might be a simpler scoring system like: winner gets 3 points; tie game each one gets 1 point; losses get nothing. That's very simplistic and doesn't work very well.
Let's say you are building a Tic-Tac-Toe gaming platform using that system. You have some players that have been using that score system for a very long time. Then, the World's best Tic-Tac-Toe player joins your platform. She's going to have a hard time getting to the top, and it's not because she's not good at the game, mostly because of how the system works. Let's say the current best player has a record of 900 wins, 800 losses, 900 ties. That's 3600 points. She would have to play 1200 matches and win them all to take the place of the current best player.
You might think this is ok, but.. think about it. What if, by random chance, she plays against the current best player and wins every time. She gets the same amount of points as she would get by playing against someone not very good at the game. That doesn't feel right.
To put it simply, Elo Rating Systems will take a few other things into consideration when you are calculating how much each player gets (or loses!) after a match based on each player's current score, their played matches, and/or whether or not there's "luck" at play.
There is a PHP package we can use here, it can be as simple as:
use Zelenin\Elo\Player;use Zelenin\Elo\Match; $player1 = new Player(1200);$player2 = new Player(800); $match = new Match($player1, $player2);$match->setScore(1, 0) ->setK(32) ->count(); dump([ 'player-1' => $player1->getRating(), 'player-2' => $player2->getRating(),]);In this match, we have one player with a current score of 1200 points and another with a score of 800 points. They are playing and the player with the lowest score wins, so their after-match score would be:
- ~1170.90 points to the player 1 (which previously had 1200 points);
- ~829.09 points to the player 2 (which previously had 800 points);
Now, consider another match where both players have relatively equal scores: player 1 has 700pts; and player 2 has 800pts. If the player 2 wins a match against player 1, the after-match score of them would be:
- ~688.48 points to player 1;
- ~811.51 points to player 2;
In the first match scenario, player 2 got more points than in the second match. That's because the first victory can be considered more difficult than the second one. Note that in both examples I'm using a fixed k-factor of 32, which is "fine", but there are more accurate ways to calculate the best k-factor for a match.
There are some issues with this rating system. As you can see, it can encourage players with high scores to not play that much (in order to not lose points) and sustain their position. To fix that, you need to consider bonuses based on activity. So if someone is sitting on a high score they either will eventually lose points or we can boost scores based on the player's activity. There are other issues as well, so check out the Wikipedia page for more details on this.
Conclusion
Whenever you have some rating system at play, consider using something like the Elo Rating Systems to compute scores. It creates a much more "fair" and fun environment for the competitors.
]]>These topics would be like chat-rooms. We sorted the topics based on the number of messages being exchanged in them. So the most-chatted topics would appear on top. But there is a problem with this approach. If a topic arises and is heated up, there are chances the topic would cool down after a while and get "stale" but always on the top. To fix that, we implemented the Reddit "hotness" algorithm based on the messages count.
There is a great write-up full of details on how the algorithm works, but the general idea is that we should implement a sorting rule that takes the number of messages in the topic and when the topic was created. This way, new messages will give a topic a boost, but eventually, new topics will be "hot" no matter the number of messages a topic has.
To do that in SQL, we would have something like this:
SELECT topics.*, LOG10(messages_count + 1) * 287015 + UNIX_TIMESTAMP(topics.created_at) AS topic_hotnessFROM topicsORDER BY topic_hotness DESCIf you using Eloquent, you could write this query like this:
App\Topic::query() ->orderByDesc( DB::raw('LOG10(messages_count + 1) * 287015 + UNIX_TIMESTAMP(created_at)') ) ->get();In this case, I have a cached value called messages_count which is incremented every time a new message is sent to that topic. I could use sub-queries here, I guess. Not sure about performance, though. The created_at field is stored as a Unix timestamp. In the app I mentioned, I think we used stored-procedures and triggers to update a score field (I don't have the code anymore to look back at it). Not something I would do these days, to be honest.
Check the article I linked above for a very detailed explanation of the problem and this solution. With a random dataset, this query would generate the following JSON payload:
[ { "id": 2, "title": "ab reprehenderit ipsa", "messages_count": 100, "created_at": "2020-08-05T20:32:00.000000Z" }, { "id": 3, "title": "laborum quis qui", "messages_count": 500, "created_at": "2020-08-02T20:32:00.000000Z" }, { "id": 1, "title": "odit est consectetur", "messages_count": 10, "created_at": "2020-08-07T20:32:00.000000Z" }]There are other more advanced algorithms at play in Reddit related to ranking, which are based on up/down votes (see here and also here - this one even contains SQL and Excel versions of the ranking so you can toy around with spreadsheets if that's your thing).
For reference, here's what the results would be to sort by date:
[ { "id": 1, "title": "odit est consectetur", "messages_count": 10, "created_at": "2020-08-07T20:32:00.000000Z" }, { "id": 2, "title": "ab reprehenderit ipsa", "messages_count": 100, "created_at": "2020-08-05T20:32:00.000000Z" }, { "id": 3, "title": "laborum quis qui", "messages_count": 500, "created_at": "2020-08-02T20:32:00.000000Z" }]And here's what it would look like if we sorted it by messages_count:
[ { "id": 3, "title": "laborum quis qui", "messages_count": 500, "created_at": "2020-08-02T20:32:00.000000Z" }, { "id": 2, "title": "ab reprehenderit ipsa", "messages_count": 100, "created_at": "2020-08-05T20:32:00.000000Z" }, { "id": 1, "title": "odit est consectetur", "messages_count": 10, "created_at": "2020-08-07T20:32:00.000000Z" }]Conclusion
These algorithms can be used to create more "relevant" ways to consume the data in your application. We can adapt it to our needs, depending on what our data looks like.
Bonus
You can wrap the hotness algorithm behind a query scope and add that dynamic field to the query when you need it, like:
App\Topic::query() ->withHotnessScore() ->get()Where the query scope would be something like:
class Topic extends Model{ public function scopeWithHotnessScore(Builder $query, array $columns = ['topics.*']) { $query ->select(array_merge($columns, [ DB::raw('LOG10(topics.messages_count + 1) * 287015 + UNIX_TIMESTAMP(topics.created_at) as hotness_score'), ])) ->reorder('hotness_score', 'DESC'); }}If you know a more elegant way of adding this dynamic field to an Eloquent query, let me know.
]]>I graduated in 2012 in System Analysis (4 years) and a few years later I returned to get a specialization in Software Engineering (2 more years). Counting by when I started college (2009), I have 11 years of experience in this field (holy sh*t). But that's not how I personally count. I got an internship in web development half-way through my graduation and was hired as a programmer 1 year later, around 2011. That makes it almost 9 years of professional experience. And I still struggle with impostor syndrome. It comes and goes, and I'm not really sure what triggers it yet.
Anyways, I started trying to beat this up and that's where this book enters. See, my graduation course wasn't deeply technical on how computers work. Instead, it was a mix of high-level, general concepts on programming (intro to programming, data structures, some networking, a few languages, databases), a bit of business stuff (management, accounting, sociology), and some math too (algebra, statistics, calculus). It wasn't computer science.
So I started looking for books to fill in some gaps that I don't even know I have (finding these gaps is part of the process as well). That's where I found The Secret Life of Programs book. And it's amazing. It goes from bits and electronics to logic gates and circuits, going up into data structures, then programming languages, and then how the browser works, then we get to see a Javascript program and its C version to understand the difference between high-level languages and low-level languages, then it touches on security and machine intelligence (machine learning + big data + artificial intelligence), and ends with some "real world" considerations. That's the gist of the book. I highly recommend it if you don't have a very "computer science" background, like me.
As much as I want to talk about all topics the book covers, it isn't practical (and probably illegal), but I wanted to share some learning and highlights I got from the book. Let's begin.
What is programming?
Right from the beginning, the author goes over the importance of low-level knowledge. He starts by saying he agrees with the definition of computational thinking by Stephen Wolfram:
formulating things with enough clarity, and in a systematic enough way, that one can tell a computer how to do them.
That's a very good statement. In order to write programs, we have to understand the problem (and domain) involved. Lack of knowledge about the problem (what to actually do and what we shouldn't care about) are directly projected into the codebase. You can see all the uncertainties about the domain in the code (sometimes even feel it). The author agrees with Wolfram's general idea but disagrees when Wolfram suggests that we don't need to learn "low-level" details.
One thought I've just had while writing this is that we try to add more and more constraints to our codebases as an attempt to make correct systems, but I think a better understand of the problem we are trying to solve (or improve) usually pays off better than any coding technique you might find out there. That's why ShapeUp and Event Storming can help, IMO. Anyways, back to the book review.
There is also a short definition of programming as a 2-step process:
- Understanding the universe; and
- Explaining it to a 3-year-old.
The difference between coding, programming, engineering, and computer science is also really good:
- Coding: the knowledge of some codes to make certain things (being able to "make the text bold" in an HTML page). Usually, a coder is proficient in one special area (HTML or JS, for instance);
- Programming: knowing more than one special area or two;
- Engineering: the next step up in complexity. To quote the author "in general, engineering is the art of taking knowledge and using it to accomplish something";
- Computer science: the study of computing. Often, programming is mixed up with computer science. Many computer scientists are programmers, but not all programmers are computer scientists. Discoveries in this field are used by engineering and programmers.
The author also makes an interesting comparison with doctors regarding generalists vs specialists. He says that in medicine a specialist is a generalist that picks one area to specialize. Whilst in programming, a specialist is someone that knows a particular area, but usually doesn't have a general understanding of the whole picture. He would prefer our field to be more like the medical field. I found this comparison interesting. It aligns with the idea of the T-shaped skills.
Talking to computers
The book spends almost half of its contents talking about very low-level details from bits to hardware. Although there were parts here that I wanted to skip (I noticed that I'm not very much into computer details, like the electronics parts) there was some really helpful stuff in this part. It goes over everything from what is a bit, to how can we represent negative numbers in binary, bit addition, and other operations. It's all very interesting.
The part about representing time in computers was really good. Humans use periodic functions to calculate time, like the rotation of the Earth (1 full rotation == 1 day), or the time it takes for a pendulum to swing in old clocks.

But computers work with electronics, so an electrical signal is needed as the periodic function. Enters oscillators and quartz crystals. The crystal generates electricity when you attach some wires to it and give it a squeeze. Add electricity to the wires and it bends (see this video and the following one for more info on how quartz crystals generate electricity.) So, in order words, if you apply electricity to a crystal, it will send electricity back to you, and this happens in a very predictable time schedule, making it a good oscillator.
He also goes into very low-level details on why we use binary in computers and how all the analog-to-digital conversion happens. There were some nice explanations on bit numbering. I found the naming really good "least significant bit" and "most significant bit" are called that because changes in the left bits result in bigger changes in the actual value (just like in decimal, if you change "11" to "21" you almost doubled the value while from "11" to "12" is a relatively small change).

He also explains "shift" operations in binary:
- Shift left: move all bits 1 position to the left, throwing away the MSB. Practically this multiplies the value by 2, but it's much faster than multiplying by 2 in CPU time;
- Shift right: move all bits 1 position to the right, throwing away the LSB. Practically, this divides the value by 2, but (again) much faster.
"0100" binary in decimal is "4" if you "shift-left" it becomes "1000", which converted to decimal again is "8". If we do a "shift-right" instead, the same binary number "0100" becomes "0010", which when converted to decimal becomes "2". Cool, right? PHP has bitwise operators, so we can see it in practice here:
$ php artisan tinkerPsy Shell v0.10.4 (PHP 7.4.7 — cli) by Justin Hileman>>> $a = 4;=> 4>>> $a >> 1;=> 2>>> $a << 1;=> 8Languages can optimize our code for us and decide when to use bitwise operators. So we can actually choose to write code for humans instead of writing it for machines almost all the time.
Compilers, interpreters and optimizers
The book explains the difference between these 3, I'll try to summarize it here:
- Compiled languages turn the source code (the high-level programming language we wrote) directly into machine code (opcode). Compilers do that translation. The machine code is usually generated to a specific target machine, that's why you need to generate binaries for Intel and AMD processors because the opcode on those architectures are different;
- Interpreted languages don't result in machine code (for "real" machines - as in "hardware"). They usually have a virtual machine as a target. It's up to the interpreter to either generate the opcodes from the directly from the source code or cover that source code to some kind of "intermediary" language that is easier to translate to opcode.
Compiled languages are usually faster, but these days computers are so fast that we can afford the luxury of using interpreted languages without many problems in most cases. That can't be said for embedded systems, where resources are usually scarce.
Optimizers can be used to, well, optimize the generated machine code. Here's Rasmus Lerdorf (creator of PHP) talking about compiler optimization in PHP. With optimizers, we can generate smarter machine code by getting rid of static, unused statements or by moving opcode around for the sake of optimization (like when you do a calculation inside a loop using values defined outside of the loop. The optimizer is able to detect that and move the opcode to generate the calculation to outside the loop for you.)
One interesting thing here is that I realized I considered Java to be a compiled language. But, according to the author, it's actually interpreted. There are some hints in the name of the Java Virtual Machine (JVM) but for some reason, it was sitting with the compiled languages in my mind. C and Go are examples of real compiled languages. Just because a language has a compiler it doesn't mean it's "compiled".
The browser
I felt like home in here. It goes over how the browser works, what is HTML, what is the Document Object Model (DOM), what is CSS, what is JavaScript, etc. Then it goes by saying that browsers are actually big interpreters.
Then it goes ahead and implements a game in JavaScript using the tree nature of the DOM itself to build a knowledge tree. After about 40 lines of JS code, the "guess the animal" game was done. He then writes the C portion of it, forcing him to explain I/O and memory management and all the low-level details that we didn't have to worry about in JS running in the browser. No need to say that the C version was longer, right? About 171 lines long.
Project management
After some more advanced topics, the book gets to a "real world considerations" chapter where the author talks about the short history of UNIX, dealing with other people, aligning expectations with stakeholders and managers, project management stuff.
I really liked the development methodology section. He mentions that sometimes it feels like we are treating methodologies as "ideology". It's all about doing some rituals over and over and hoping to deliver the project on time and on budget. His advice was: don't take any methodology too seriously, as none of them actually work in their pure form. His chart pretty much summarizes all methodologies:
The project development cycle goes like this:
- Understand the problem you are trying to solve with the stakeholders;
- Figure out a way to build it internally, iterating over design decisions with your peers;
- Validate if you are heading in the right direction with your stakeholders again;
- Repeat until the problem is solved.
There were also some practical project design tips, like:
- Ideas start by writing them down. Don't code it right away, write them down first and try to fully understand the problem you are solving;
- Create prototypes, but throw them away. They don't have to be perfect, nor use "real implementations" of anything;
- Don't put a hard deadline on prototypes. It's usually creative work as we don't know exactly what we are prototyping, so it's hard to come up with a realistic schedule anyways;
He also mentions a bit about abstractions and how we should avoid having too many, and shallow abstractions. Prefer a few, deeper abstractions instead. He mentions the Mac API. The Apple Macintosh API set of books was released in 1985 with 1200 pages in total. And it's completely obsolete now. He suggests that one of the reasons could be because the Mac API was very wide and shallow. Compare that with UNIX 6, released in 1975 (10 years earlier), with a 312-page manual. The UNIX API was narrow and deep.
One example is the Files API. On UNIX almost everything is a file (or acts as a file). Other operating systems had different system calls for each type of file, but UNIX had a unified API (file descriptors). That means that you can use the UNIX cp command to copy a file on your local file system to a different location, or send it over the network via an I/O device (like sending a file to your printer, for instance).
Other topics
I only mentioned the topics that I found really relevant to me, but the book goes over way more topics than I cover here, like:
- Using math to cheat: how we can use math to compress images, draw figures on canvas, etc;
- Security: giving us a basic understanding of security in general. Touches on cryptography and some "not so easy to spot" threats;
- There is also way more hardware stuff than I mentioned here.
I also got a copy of "The Imposter's Handbook" that I'm going to be reading soon (I have some other books in the pipeline, like "The Design of Everyday Things" and "The Software Arts"). I just felt really excited about finishing this book.
]]>I wrote an introduction on Inertia.JS in the madewithlove blog!
]]>Some relevant links:
- The Example App
- "Hybrid sweet spot: Native navigation, web content" blogpost
- "Turbolinks: I can't believe it's not NATIVE" talk by Sam Stephenson
- Turbolinks Android Bridge
- DHH's tweet confirming Turbolinks Android Adapter v2
- Turbolinks React Native Adapter
- "Basecamp 3 for iOS: Hybrid Architecture" blogpost
I feel like it's missing the point. It's again saying that monoliths are a "thing of the past", which is just silly.
I don't think of Serverless as the opposite of the Monolith. Nor as a "next step after Microservices". Quite the contrary, Serverless is a great environment to deploy your monolith.
Monoliths consists of 3 layers (entry-points): web, worker, and scheduler (clock). They need a connecting message broker, usually Redis or SQS to connect these pieces, and a database.
If you think of Serverless as a deployment target, your deployment pipeline should generate 3 functions: web, cli, and queue.
All these share the same runtime, but they have different "roles". The web function will invoked whenever a new HTTP event happens on your Serverless environment. It might send background jobs to SQS, which will cause another event on your Serverless enviroment and invoke the queue function to handle it.
You still develop it locally as a monolith, but your deployment target is Serverless.
That's the approach used for services such as Laravel Vapor, for instance.
Due to serverless, they can use different services such as Algolia, Stripe, Lambda and others to get that power and those features and integrations.
This is misleading. You can also be "serviceful" and leverage most of these 3rd-party services to reduce the same operational costs as a monolith application. No need to wait for a "microservice" to use something like Algolia or Stripe.
Update (15/02/2020): Mohamed Said from Laravel has posted a talk explaining Laravel Vapor a bit more. Check it out here.
]]>In that talk, she goes on refactoring some code into smaller objects and giving them appropriate names. Eventually, she gets into this a very nice design with no branching in code (conditionals), which leads to easily testable code. I like it a lot.
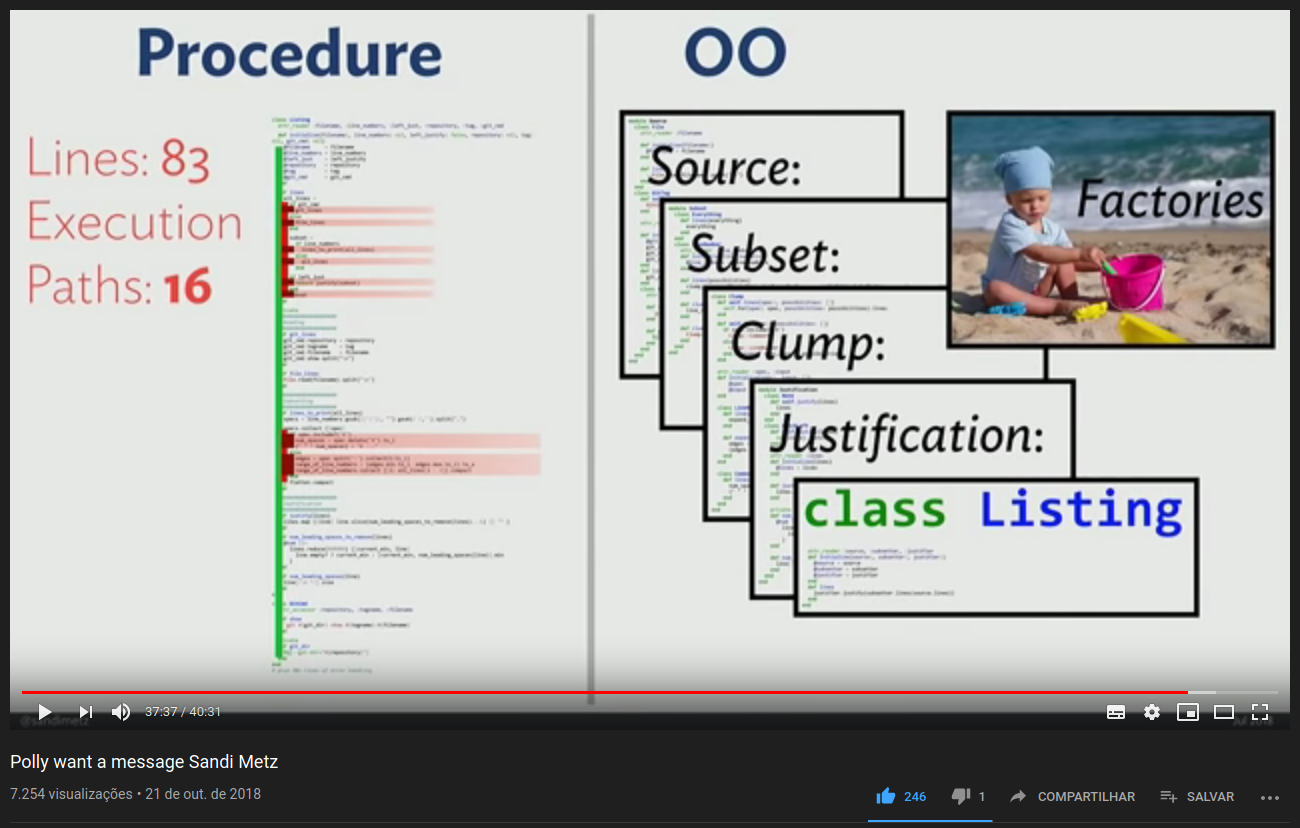
One thing that got me thinking was that "Listing" class. She has talked about such classes before in other talks. I remember another talk where she mentions that "the controller should only talk to a single class". Well, the Listing is that class (I think).
Recently, in a podcast, they explored that view a bit more, and it was confirmed that this is indeed the class that the controller should talk to.
During the interview, they go over another example referring to a ReconcilableCharges class that talks to the AR models (or objects that respond to messages sent to the AR models). She even goes into the folder structure and states that these are the only classes allowed to interact with the AR models.
The folder structure could look something like this:
app/models├── ar│ ├── order.rb│ └── payment.rb├── orders.rb├── payments.rb└── reconcilable_charges.rbWe have the Active Record models inside the "models/ar" folder, while the domain classes living outside. Some people call these "service objects", or "interactors", you name it.
The point is: these classes form the domain of the application. They are the ones talking to the Active Record models. But they can do much more than that.
I think I like this structure. I've seen this before in the Phoenix Framework. This looks similar to what they call "contexts".
Taking to the extreme
I saw ideas like this taken to the extreme a few times. However, I think the problem I saw wasn't related to this structure, it was more about a misunderstanding of the Single Responsibility Principle (SRP). The idea that those contexts (actors?) classes only having a single method or "do only 1 thing" and you end up with a bunch of behavior spread all over a handful of classes, when in fact those affordances belong to a single actor in the system.
The SRP is all about the reason to change. Not how many methods or lines of code a class has. It means that your context should have one reason to change. It should answer to a single stakeholder.
That to say that these context classes can have many methods. Well, I prefer to say "a few" instead of "many", but you got it.
If you put logic in classes that do only 1 thing, you have procedural code wrapped in a class. Or a Transaction Script. It might feel like it's easier to maintain because, at the end of the day, you have very shallow classes that do only 1 thing. But it's not cohesive.
Object-Oriented code is all about building simulations. Abstractions (or simplifications, if you prefer) of the real world (aka. objects) that communicate through message-passing (method calls, in class-based languages).
Wrapping up
Although I like this idea, I have to be honest. I still have scars from code-bases where the "only 1 thing" rule was enforced, and they itch. I can see the usefulness of structures like this, but I can also see teams "mandating" that the AR models are never used anywhere else.
Ever since I started creating more controllers for my apps (see here and here) I stopped worrying about more "robust architectures" (whatever that means to you) and started enjoying the code much more. Simpler and smaller controllers lead to a cohesive system.
This doesn't mean that I only have AR models in my domains, not at all. There are still places for plain-old objects. And you know those places. Those concepts that don't really match with any of your existing models and might depend on or fit in multiple of them. Yeah, those. Extract them to a class, name them properly and inject their dependencies (see here).
]]>Before I found Laravel, I had been using other frameworks and even had to maintain a "pure" PHP application that I inherited for a while, and if you only take one idea out of this article: use a framework.
Some people don't like frameworks. I don't know if that's because they think they can do better than a group of very experienced folks working collaboratively on something or if it's something psychological.
Others think that just by "using" a framework it makes their application as robust as the framework itself. Even better if the framework is fully broken in components or, better yet, if they are "micro".
Some even use frameworks as some kind of "competitive advantage" to sell their work "we use this framework because it gives us all the structure we need to write robust web applications with high code quality". Well, I'm not convinced this is true.
See, it's not that you use a framework that matters, it's how you use it.
When it comes to software, I like to think that there are many solutions to the same problems. And most of the time the possibilities are endless (or so it seems).
Frameworks provide the building blocks you can use to write your own stories in the form of software. And, given that there are many different solutions to the same problem, you can pick the ones that better fit the building blocks you are given by sticking to the frameworks' conventions.
It's not like the framework "limits" you. Quite the contrary: it empowers you. Not just you, but your team too. Especially small teams (but also big teams!).
To build a modern application these days, you need a lot of powerful building blocks. We are not talking about sending e-mails, submitting forms, and things like that. Think highly interactive applications: background jobs, notifications, Web Sockets, etc.
And if you are going to build something like that today on your own without a framework, well, good luck. It's not impossible, it's just that you would be much better off by using a framework.
Need to send notifications and they can be via SMS, E-Mail, or Dekstop Notifications? Sure, no problem, the framework already has the abstractions for that built-in. "This report is really slow, and sometimes it times-out" what if you make it async? Dispatch a job, generate it in the background, create a temporary link, and send it back to the customer so they can download it. Easy when you already have all the building blocks available.
Don't overthink it either. Try as much as you can to write the simplest code possible. Something that is easy to delete. Don't put layers and layers of abstractions just because someone told you to. Think. Does this make your code easy to read/understand? If you want to remove this feature entirely next week, how hard would it be?
This is definitely one of the things that fit the category of "easier said than done". Simplicity is hard to achieve.
Next time you are starting a project, use a framework. Take a look at Laravel, for instance. You might find it gives you most of the things you need (and even some that you don't even know you need yet, but will be very handy very soon).
And, as the Laravel CLI application generator says: Build something amazing.
]]>We've worked for a lot of different companies. What is the top lesson we can share with startups that we've learned from our experience?
This was the KnowYourTeam question this week at work, and I found it so interesting that I wanted to share my answer here as well.
To be honest, I would recommend Getting Real. I've been re-reading it, and it's amazing how a book from 2006 is still so relevant these days when it comes to building web applications.
Some of the key points to me:
- Your v1 application should have a small team (3 people): fewer debates, faster decisions, more actions (from "The Three Musketeers" chapter);
- Build only the essential parts. Start with the core of your application, and build it backward. It's also easier to validate if the idea is possible, and where the knowledge gaps of the team are. Maybe a fix would be bringing someone with experience in the technology (if it's new) or just that it's not worth building it. The faster you know this, the better (summary of "Build Less", "Less Software", "Fix Time and Budget, Flex Scope", and "What's the Big Idea" chapters)
My experience re-validates the lessons from the book.
Some other chapters that I enjoyed:
]]>After researching for a while I found a few good resources on the subject. The most attractive one is Elasticsearch. Yes, you can go far with full-text search and other searching techniques, however Elasticsearch is very handy and comes with a variety of useful features.
I wrote about using Elasticsearch and how to integrate it with your Laravel application in the madewithlove's blog. Check it out if you like it.
Cheers,
]]>Containers really shine when your service has a single OS process (or have the main process that handles children processes). That process is the PID 1 of the container. This makes scaling containers a breeze. For instance, if you need more processing power, you can spin up more containers in your cluster. This way of building and running containers works fine with languages that are self-contained, like Go or Node, for instance, where you can spin up a single process that binds to a port and that's it.
But when it comes to PHP, at least the more traditional way of running PHP, it gets tricky. In the pre-container era, the most common way of running PHP applications was with Nginx+phpfpm. This works out really well, actually. But in the container era, it's tricky. To run PHP like that you need two processes: Nginx and fpm. They will talk with each other via Unix sockets (basically a shared file in the same filesystem).
And both processes are important for the container. You want your container terminating if either of these processes dies, so the orchestrator can detect it and spin up a new container to take over. They are equally important. How can you make it so they are both handled as PID 1 in the container?
Some folks just give up and go with apache2+modphp, which is actually fine, I guess (I have done that myself), but I would prefer to stick with Nginx and fpm. If you are like me, there is a way: process supervision.
Process Supervision
A process supervisor is exactly what it sounds like: some process that the only job is to watch other processes. If they are running, or if they have stopped, things like that.
The most common supervisor might be Supervisord, and in most cases, it does the job really well. I've used it for running queue workers and schedulers, for instance. But it's not suited for running as the init process in the era of containers, it even states that in the first page of the documentation:
It shares some of the same goals of programs like launchd, daemontools, and runit. Unlike some of these programs, it is not meant to be run as a substitute for init as “process id 1”. Instead it is meant to be used to control processes related to a project or a customer, and is meant to start like any other program at boot time.
That's ok, actually. We have other options, and some are even linked in Supervisord's documentation. One option that is not listed is called: S6.
S6 Overlay
S6 all the functionality required for running as the PID 1 in a container, essentially:
- Well, process supervision; and
- Forwarding signals (any signals the PID 1 receives, it will forward to the other processes, so they can terminate gracefully or re-read the configs);
There are other functionalities built-in in S6, but these are the main ones, as I see it. You can read more about S6 here.
Let's see what it looks like to add S6 overlay to our Docker images.
Example
I've created a repository here so I won't go over it step-by-step. The Dockerfile has some comments if you are curious. To run this app you first have to build the Docker image:
git clone git\@github.com:madewithlove/php-s6-overlay-demo.gitcd php-s6-overlay-demo/docker build -t php-s6-demo-app:0.0.1 .docker run --rm -p "8000:80" php-s6-demo-app:0.0.1You should see an output like:
[s6-init] making user provided files available at /var/run/s6/etc...exited 0.[s6-init] ensuring user provided files have correct perms...exited 0.[fix-attrs.d] applying ownership & permissions fixes...[fix-attrs.d] done.[cont-init.d] executing container initialization scripts...[cont-init.d] done.[services.d] starting services[services.d] done.This account is currently not available.[10-Jul-2019 17:55:48] NOTICE: fpm is running, pid 178[10-Jul-2019 17:55:48] NOTICE: ready to handle connectionsNice! And if you open your browser, you should see the familiar phpinfo screen:
This means everything is working! Great. Now, you can go ahead and kill the docker container by pressing Ctrl+d in the container terminal screen. You should see some output that S6 is sending the services the TERM signal and then the KILL (for the ones that did not handle the TERM):
^C[10-Jul-2019 18:04:39] NOTICE: Terminating ...[10-Jul-2019 18:04:39] NOTICE: exiting, bye-bye![cont-finish.d] executing container finish scripts...[cont-finish.d] done.[s6-finish] waiting for services.[s6-finish] sending all processes the TERM signal.[s6-finish] sending all processes the KILL signal and exiting.Great! That was it.
Conclusion
Some people might argue that containers are meant to be single-process services, and maybe they are right by the book, but I do think it's fine if you need multiple processes in a single container in this case. As always: it depends.
You can split your application in two containers one for the Nginx and another for the fpm processing and make them talk via TCP sockets, but that gets weird, you have to add a copy of your assets (usually the public/ folder to your Nginx image, and you also need that in the fpm container). It would be just easier to spin this application as a single container.
There are no silver bullets, only trade-offs. And in this case, they are worth it, IMO.
Cheers.
P.S: Maybe worth saying that the S6 Overlay init script (located at /init after you add the S6 Overlay files to your image), must be the ENTRYPOINT of your container, this way you can override the default command and S6 will still apply process supervision to your command. This is very useful when running workers, you can re-use the same container image and change the command to something like php artisan horizon and S6 will apply the process supervision on this process as well.
]]>Requirements
You will need some tools installed, make sure you have them on your local machine:Docker
- Kubernetes' kubectl
- Digital Ocean's doctl
- A Digital Ocean account
Containerizing a PHP Application
First of all, we are going to start from scratch here, so let's create the folder that will wrap all of our files:
mkdir php-terraform-kubernetes-example/Great! From now on, we are calling this folder the root path.
Now, let's create the World's simplest PHP application. Add an index.php file under
<html lang="en"> <head> <title>Simplest PHP APP</title> </head> <body> <h1>Hello, World!</h1> <h3>From host: <?= gethostname(); ?></h3> </body></html>Since having PHP installed wasn't a requirement, we are going to use Docker to test this application. For that, let's create the World's worst PHP Dockerfile. Create a Dockerfile inside <root>/app/ with the following content:
FROM php:7.3 WORKDIR /app COPY . /app CMD ["php", "-S", "0.0.0.0:80", "-t", "public/"]This Dockerfile describes how we want our Docker image to look like. It contains all the steps to create (and recreate) the Docker image for our containers. Let's dissect the lines instructions on it:
- FROM php:7.3: This tells Docker that our application Docker image is based on the official PHP image for the 7.3 version. Official images do not require an organization/username prefix and can be found in the default Docker Registry - Docker Hub;
- WORKDIR /app: This sets the path /app inside our container as the working directory, which means that any command running inside the container will from this directory as context;
- COPY . /app: This copies all files from the context path to the /app path inside the container;
- CMD ...: This is the default command that the container will run. We can override this at runtime, but that's out of the scope of this article.
Alright, with that covered, let's build our custom Docker image by running the following command:
docker build -t tonysm/demo-php-app:0.0.1 -f app/Dockerfile ./appSending build context to Docker daemon 3.584kBStep 1/4 : FROM php:7.3 ---> f0357c41bff5Step 2/4 : WORKDIR /app ---> Using cache ---> fac311810559Step 3/4 : COPY . /app ---> Using cache ---> 88f78910921eStep 4/4 : CMD ["php", "-S", "0.0.0.0:80", "-t", "public/"] ---> Using cache ---> 1165b21c4c06Successfully built 1165b21c4c06Successfully tagged tonysm/terraform-k8s-demo-app:0.0.1Here's a poor explanation of what is going on here:

Great. Our image was successfully built. You can find your Docker image in your local images with the following command:
docker image ls | grep tonysm/terraformtonysm/terraform-k8s-demo-app 0.0.1 e522d9fbc93b 5 seconds ago 367MBNice, let's run this image locally to test it out:
docker run -p 8000:80 tonysm/terraform-k8s-demo-app:0.0.1No output, which (in this case) means it's working. Open http://localhost:8000 in your browser and you should see something like this:
Great! Now, let's push this image to Docker Hub. You need to create an account there, so go ahead, I'll wait.
Now that you have an account in Docker Hub, you also need to authenticate you local Docker CLI running docker login and typing your credentials there. After that, we can now push our image to Docker Hub with:
docker push tonysm/terraform-k8s-demo-app:0.0.1The push refers to repository [docker.io/tonysm/terraform-k8s-demo-app]0e017f123496: Pushed5bcce6289196: Pushed5e63a0adbe83: Mounted from tonysm/dummy-php-image82c280d40dc6: Mounted from tonysm/dummy-php-image07886e8b1870: Mounted from tonysm/dummy-php-imagee01f9f2bc3a7: Mounted from tonysm/dummy-php-image4625f667b473: Mounted from tonysm/dummy-php-image0318b3b010ef: Mounted from tonysm/dummy-php-imaged7b30b215a88: Mounted from tonysm/dummy-php-image9717e52dd7bd: Mounted from tonysm/dummy-php-imagecf5b3c6798f7: Mounted from tonysm/dummy-php-image0.0.1: digest: sha256:27f939f99c2d57ca690a5afdc8de2afe0552b851d0c38213603addd1f6bba323 size: 2616In my case, some of the steps were already present in another image in my user account, so Docker knows that and doesn't have to push the same layers again. If you open your profile on Docker Hub, the image will be there, publicly available to anyone:
Great. Now, let's create our Kubernetes Cluster.
Terraforming Infrastructure on DigitalOcean
Since we are using DigitalOcean, we could go to their Dashboard and spin up a Kubernetes Cluster from there. But, let's make it more interesting by using Terraform to do that for us. It will build the Kubernetes Cluster for us and later we can deploy our application to it.
Let's start by creating the folder <root>/provision/ in our app (mkdir provision/). Terraform doesn't require any file naming convention, it will load any file ending with *.tf in our folder, so let's create a main.tf file with the following content:
provider "digitalocean" { token = var.do-token} // Kubernetes cluster with 3 nodes.resource "digitalocean_kubernetes_cluster" "terraform-k8s-demo-app" { name = "terraform-k8s-demo-app" region = "nyc1" version = "1.14.2-do.0" node_pool { name = "terraform-k8s-demo-app-pool" size = "s-2vcpu-2gb" node_count = 1 }I'm not going over line-by-line on what is going on here, just know that we are telling Terraform that we are using the digitalocean provider, and that gives us some resource types we can use, one of them is the digitalocean_kubernetes_cluster that creates the cluster for us with, in this case, 1 node (see the node_count definition). If you want to learn more, the documentation is a wonderful place.
This file requires the existence of a variable, the var.do-token, let's create a variables.tf file:
variable "do-token" { default = "(YOUR DIGITAL OCEAN TOKEN)"}Make sure this file is ignored on Git, you do not want to share your Digital Ocean token. Now, let's initialize our Terraform client:
cd provision/terraform init Initializing the backend... Initializing provider plugins... The following providers do not have any version constraints in configuration,so the latest version was installed. To prevent automatic upgrades to new major versions that may contain breakingchanges, it is recommended to add version = "..." constraints to thecorresponding provider blocks in configuration, with the constraint stringssuggested below. * provider.digitalocean: version = "~> 1.4" Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to seeany changes that are required for your infrastructure. All Terraform commandsshould now work. If you ever set or change modules or backend configuration for Terraform,rerun this command to reinitialize your working directory. If you forget, othercommands will detect it and remind you to do so if necessary.Great. Now, let's use Terraform to make a plan of action to build the infrastructure:
terraform plan -out /tmp/plan Refreshing Terraform state in-memory prior to plan...The refreshed state will be used to calculate this plan, but will not bepersisted to local or remote state storage. section: content ------------------------------------------------------------------------ An execution plan has been generated and is shown below.Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # digitalocean_kubernetes_cluster.terraform-k8s-demo-app will be created + resource "digitalocean_kubernetes_cluster" "terraform-k8s-demo-app" { + cluster_subnet = (known after apply) + created_at = (known after apply) + endpoint = (known after apply) + id = (known after apply) + ipv4_address = (known after apply) + kube_config = (known after apply) + name = "terraform-k8s-demo-app" + region = "nyc1" + service_subnet = (known after apply) + status = (known after apply) + updated_at = (known after apply) + version = "1.14.2-do.0" + node_pool { + id = (known after apply) + name = "terraform-k8s-demo-app-pool" + node_count = 1 + nodes = (known after apply) + size = "s-2vcpu-2gb" } } Plan: 1 to add, 0 to change, 0 to destroy.section: content ------------------------------------------------------------------------ This plan was saved to: /tmp/plan To perform exactly these actions, run the following command to apply: terraform apply "/tmp/plan"Terraform gives us what it plans to do in our infrastructure. It's our job to validate if everything looks ok. For this example, I think it's fine, let's apply this plan:
terraform apply /tmp/plandigitalocean_kubernetes_cluster.terraform-k8s-demo-app: Creating...digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [10s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [20s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [30s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [40s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [50s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [1m0s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [1m10s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [1m20s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [1m30s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [1m40s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [1m50s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [2m0s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [2m10s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [2m20s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [2m30s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [2m40s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [2m50s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [3m0s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [3m10s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [3m20s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [3m30s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [3m40s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [3m50s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [4m0s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [4m10s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [4m20s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [4m30s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Still creating... [4m40s elapsed]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Creation complete after 4m44s [id=81ee8486-51cb-48da-811c-14d6b3346f7d] Apply complete! Resources: 1 added, 0 changed, 0 destroyed. The state of your infrastructure has been saved to the pathbelow. This state is required to modify and destroy yourinfrastructure, so keep it safe. To inspect the complete stateuse the `terraform show` command. State path: terraform.tfstateGreat. This means our Kubernetes cluster was successfully created on Digital Ocean. You can open up your Dashboard and see the cluster as well as the nodes, but let's use the doctl CLI tool for that. To start, you need to authenticate with your Digital Ocean token:
doctl auth initAnd paste your Digital Ocean token. Now, let's list our Kubernetes:
doctl kubernetes cluster listID Name Region Version Auto Upgrade Status Node Pools81ee8486-51cb-48da-811c-14d6b3346f7d terraform-k8s-demo-app nyc1 1.14.2-do.0 false running terraform-k8s-demo-app-poolNice. Let's connect our local kubectl to that remote cluster:
doctl kubernetes cluster kubeconfig save 81ee8486-51cb-48da-811c-14d6b3346f7dNotice: adding cluster credentials to kubeconfig file found in "/home/tony/.kube/config"Notice: setting current-context to do-nyc1-terraform-k8s-demo-appFrom now on we are doing any command we run with kubectl in our cluster, like:
kubectl cluster-infoKubernetes master is running at https://81ee8486-51cb-48da-811c-14d6b3346f7d.k8s.ondigitalocean.comCoreDNS is running at https://81ee8486-51cb-48da-811c-14d6b3346f7d.k8s.ondigitalocean.com/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.Cool. Now, let's deploy our application on this Kubernetes Cluster.
Deploying on Kubernetes
We already have our image on Docker Hub (our registry), so we only have to create our Kubernetes Objects' manifests. If you are new to Kubernetes, I did an attempt to explain what these are in this blogpost, but also check the docs.
For our application, we will need:
- A deployment object for the web (our application);
- A service object to represent load balance requests to our webapp PODs.
Now, create the folder <root>/k8s/, there you can create the file webapp.yml with the following contents:
apiVersion: apps/v1kind: Deploymentmetadata: labels: app: webapp-web name: webapp-web-deploymentspec: replicas: 2 selector: matchLabels: app: webapp-web template: metadata: labels: app: webapp-web spec: containers: - image: tonysm/terraform-k8s-demo-app:0.0.1 name: webapp-web-deployment ports: - containerPort: 80 name: httpsection: content ---apiVersion: v1kind: Servicemetadata: name: webappspec: type: LoadBalancer ports: - port: 80 targetPort: http selector: app: webapp-webLet's take the time to talk about what we have here. This file contains 2 Kubernetes Objects separated by the triple dashes (---). The first one is a Deployment Object. This is typically the type of object you use on your applications. With this kind of object, Kubernetes handles the rollout of new images (you can control the deploy strategy, but by default, it is RollingUpdate, which will terminate existing PODs while creating the new ones whenever you apply a new image. The important pieces are:
- .spec.replicas: 2: tells we want 2 PODs running;
- .spec.selector.matchLabels.app: webapp-web: is what this deployment will use to "watch" how many PODs are running, so Kubernetes can control the desired amount of PODs for us;
- .spec.template: is the template that will be used to create the PODs. You can think of it as a POD object definition (I'm not sure if they call it that, but it's easier for me to think like that);
- .spec.template.metadata.labels.app: webapp-web: is very important! This is what the deployment uses in the matchLabels defition above. The deployment uses the label in this template to match with the selector to make sure it has the desired amount of running PODs for this deployment in our Cluster. This is also used when we scale down or up our PODs;
- .spec.template.spec.containers[0].image: tonysm/terraform-k8s-demo-app:0.0.1: is the container image used by this POD (technically we can have more than one container for a single POD, but that's rarely needed, tbh);
- .spec.template.spec.containers[0].ports[0].containerPort: 80: is the port this container is expecting requests;
- .spec.template.spec.containers[0].ports[0].name: http: is an alias for this port, we are using it later to reference this port instead of the number.
Alright, let's cover the service portion now. Services in Kubernetes are load-balancers that can be used to distribute load for our containers. They serve as a central reference for the PODs under it. For instance, if you have another application that talks to this application, you wouldn't have to point it to a POD. Actually, since PODs are ephemeral (like containers), this would be hard to manage. You can, however, point that application to the service instead, and the service would be responsible to send the request to the correct POD. Important pieces here are:
- .spec.ports[0].port: 80: this is the port the service is expecting requests on;
- .spec.ports[0].targetPort: http: this is the named port in our POD container the service will be sending these requests to (remember we named the container port in the Deployment template? That one);
- .spec.selector.app: webapp-web: this is the label used by the service to identify the PODs that are behind it.
There is one more caveat here. When you use a service of type LoadBalancer in the DigitalOcean Kubernetes cluster, DigitalOcean will assign an actual LoadBalancer (Ingress) that points to your service. This way, you will get a public IP bound to this service that you can use in your DNS config.
Enough talking, let's apply this object to our cluster:
kubectl apply -f k8s/deployment.apps/webapp-web-deployment createdservice/webapp createdGreat. Everything seems to be working. Let's wait a bit, because the service takes some time to create the LB for us. You can get the public IP either in the DigitalOcean dashboard or via CLI:
kubectl get svc -wNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkubernetes ClusterIP 10.245.0.1 <none> 443/TCP 7m55swebapp LoadBalancer 10.245.144.120 <pending> 80:30808/TCP 10swebapp LoadBalancer 10.245.144.120 159.203.156.203 80:30808/TCP 28mNow, if you open 159.203.156.203 on your browser, you should see our application running on DigitalOcean!
If you refresh, you can see the hostname changed!
This is because we have 2 replicas of the POD running in the cluster, as you can see with the following command:
kubectl get podsNAME READY STATUS RESTARTS AGEwebapp-web-deployment-9d6c766c6-85vvj 1/1 Running 0 32mwebapp-web-deployment-9d6c766c6-bnbpj 1/1 Running 0 32mPretty cool, right?!
Cleaning up
You probably don't want to keep this running on your DigitalOcean account, so let's clean up. First of all, let's delete the things we create via Kubernetes:
kubectl delete -f k8s/deployment.apps "webapp-web-deployment" deletedservice "webapp" deletedAlright, this should get rid of our PODs, deployments, replica sets, services, and, more importantly, our LoadBalancer that was assigned to the running service.
Next, let's use terraform to delete the Kubernetes cluster and running nodes for us:
cd provision/terraform destroy...Plan: 0 to add, 0 to change, 1 to destroy. Do you really want to destroy all resources? Terraform will destroy all your managed infrastructure, as shown above. There is no undo. Only 'yes' will be accepted to confirm. Enter a value: yes digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Destroying... [id=37b9cb67-d8cc-468d-a017-2102c2d87246]digitalocean_kubernetes_cluster.terraform-k8s-demo-app: Destruction complete after 1s Destroy complete! Resources: 1 destroyed.Everything was erased (it might take a few seconds for things to disappear from your Digital Ocean dashboard).
Wrapping up
Alright, that was a long ride. After all this, this should be your current file structure:
tree ..├── app│ ├── Dockerfile│ └── public│ └── index.php├── k8s│ └── web.yml└── provision ├── main.tf ├── terraform.tfstate ├── terraform.tfstate.backup └── variables.tf 3 directories, 7 filesThe terraform.tfstate inside the provision/ folder is where terraform keeps your infrastructure state (ips, resources creates, things like that). When you are working on a team, you probably want that state not on your local machine, but living somewhere where your teammates can also use to manage the cluster. That can be achieved by using a share S3 bucket in your backend. If you are using Digital Ocean, they have a service called Spaces, which can also be used instead of AWS S3, as they implement the same protocols.
That's it for now, I hope I have sparked some interest to you on the topic. This declarative way of doing things is becoming way more common these days, and it's everywhere: on your frontend (React and Vue), as well as in your infrastructure.
This also enables a thing we are going to talk about next: GitOps.
See you soon!
]]>In this talk, I walk-through a problem of a server provisioning application, where we need to deal with long-running operations (like install dependencies in a server), and how to approach that using Queues and Workers. Then we jump in to enrich the UI with some real-time feedback using WebSockets.
]]>If you are into Laravel and/or testing, check it out at madewithlove's blog.
]]>If you are into Laravel, Docker, and/or Kubernetes, check it out at madewithlove's blog.
]]>Check it out here:
]]>If you are into Laravel and/or WebSockets, check it out at Pusher blog.
]]>